

Итак, пользователи вашего приложения уже жалуются на долгую загрузку данных, а серверы едва справляются с нагрузкой. Одна из возможных (и частых) причин в том, что API пытается выгрузить тысячи записей за один запрос. Без пагинации базы данных захлебываются под тяжестью SELECT-запросов, а клиенты уходят к конкурентам, не дождавшись ответа.
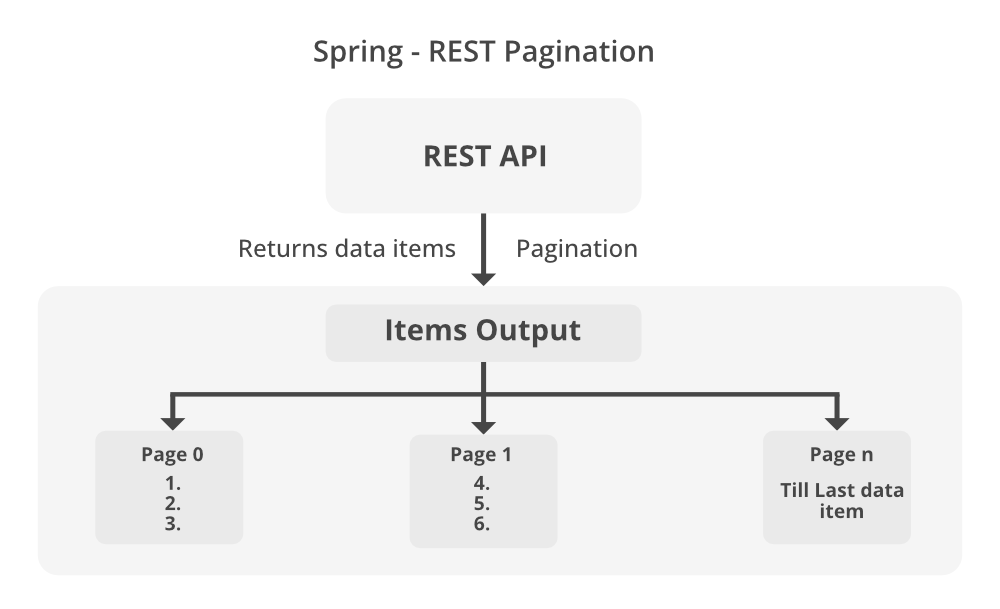
Пагинация — это не просто разбивка на страницы, а ключевой инструмент для баланса между производительностью и стабильностью. Она снижает нагрузку на серверы, ускоряет время отклика и помогает удерживать пользователей. Но здесь кроется подвох: неправильная реализация (например, использование offset вместо курсора) может только усугубить проблему.
Почему пагинация так важна
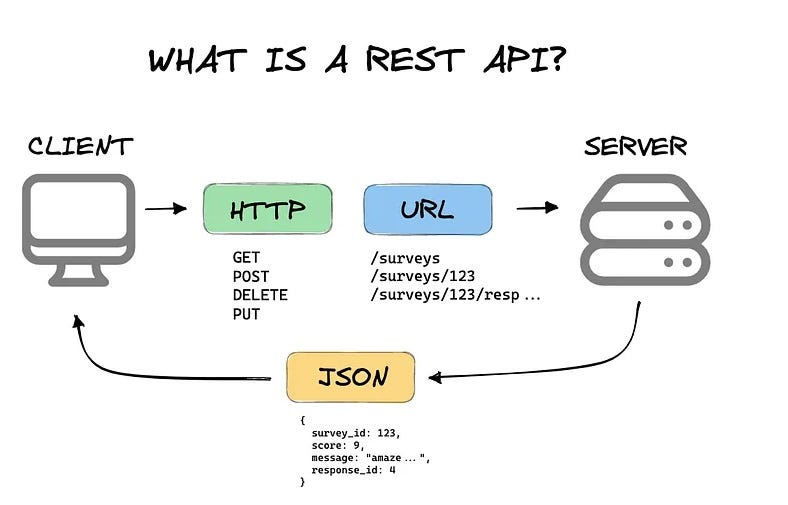
Пагинация — это фундаментальная техника при работе с API, особенно в эпоху больших данных. REST API, в свою очередь, — это мост между клиентом и сервером, который позволяет им обмениваться данными.
Кстати, пагинация полезна не только для REST API. Например, в SFTP-соединениях или при работе с базами данных через SSH, где передача больших файлов/записей может замедлить работу, пагинация помогает разбивать данные на части. Но это уже тема для отдельного разговора. А пока запомните: REST API + HTTPS + пагинация — залог стабильности в цифровой эпохе.
Продолжим. Представьте мобильное приложение банка: вы открываете историю операций, а оно в ответ запрашивает данные у сервера.
И тут начинается самое интересное. Если отдать пользователю сразу всю историю его транзакций с 2015 года, база задохнется, сервер ляжет, а приложение превратится в черепаху, которая бесконечно подгружает данные. Да и пользователю не нужен весь массив сразу — ему важно видеть только последние платежи.
Вот тут нам и поможет пагинация. Вместо того чтобы отправлять клиенту тонны данных, сервер выдает их порционно: скажем, по 50 транзакций за раз. А если нужно больше — клиент запрашивает следующую страницу. В результате API остается быстрым, сервер не задыхается, а пользователь получает данные мгновенно.
А теперь представьте, что пагинации нет. Что может пойти не так? Да почти все.
Рост объемов данных
Уже в этом году объем глобальных данных может достигнуть 181 зеттабайт, согласно прогнозам IDC и других источников. Некоторые причины этого — рост популярности устройств интернета вещей (IoT), обработка данных в реальном времени и расширение облачных хранилищ. Кстати, зеттабайты для большинства людей — это некая абстракция, потому что в повседневной жизни и работе большинство из нас с такими цифрами не сталкивается. Так вот, один зеттабайт — это секстиллион (1 000 000 000 000 000 000 000) байт или тысяча архивов Netflix.
Запросы без пагинации станут нежизнеспособными из-за нагрузки на сети и серверы. Это связано с тем, что обработка больших объемов данных без пагинации может привести к длительному времени отклика и перегрузке серверов.
Далеко ходить не будем, все мы знаем TikTok, соцсеть с более чем 500 млн пользователей. Они могут генерировать до миллиарда запросов в час. Без пагинации задержки могут превысить 10 секунд, что приведет к значительной потере аудитории. При этом я хочу заметить, что масштабируемость TikTok обеспечивается не только пагинацией, но и комплексом внутренних решений: алгоритмами балансировки нагрузки, многоуровневым кэшированием, оптимизацией запросов к БД и другими компонентами архитектуры. Но эти механизмы заслуживают отдельного детального разбора — возможно, в будущих статьях.
Что может стать ценой ошибки
Отсутствие пагинации может привести к серьезным финансовым потерям и проблемам с пользовательским опытом.
Затраты на серверы
Без пагинации вам потребуется больше серверов для обработки запросов. Это увеличивает затраты на инфраструктуру. Отсюда — излишние расходы на серверные мощности и потенциальные проблемы с отказоустойчивостью.
Уход пользователей
Если страница долго грузится (или долго не грузится), пользователи ее закрывают и открывают другую. Исследования показывают, что если страница загружается дольше трех секунд, 53% мобильных пользователей просто уходят. В e-commerce каждая секунда задержки может снижать конверсию на 7%. Без эффективной пагинации, например, с использованием OFFSET, запросы могут становиться все медленнее по мере роста данных, что напрямую влияет на пользовательский опыт.
Снижение поискового ранжирования
Если контент грузится слишком медленно, поисковые системы вроде Google могут понизить сайт в выдаче. Внедрение эффективной пагинации, скажем, с использованием keyset-based подхода, помогает сохранить быструю загрузку страниц, улучшая SEO-показатели.
Пагинация в деле
Я хочу вам показать свой пример реализации и объяснить на пальцах, в чем же преимущество, — на примере создания приложения для заметок. Представьте, что просите у ассистента список всех проектных задач за год, а он начинает зачитывать их подряд: «План проекта, риск-матрица, митинг с клиентом, ретроспектива…» — и так 200 пунктов. Терпение заканчивается на пятой задаче, а сервер к этому моменту уже дымится. Именно так работает API без пагинации: он пытается выгрузить все данные разом, замедляя систему и теряя пользователей.
Что не так с загрузкой всего и сразу? Во-первых, время ответа превышает две секунды. Пользователь уже успеет заскроллить весь TikTok. Во-вторых, трафик — 100+ КБ на запрос. Для мобильных приложений это как тащить кирпичи в кармане. В-третьих, из-за нагрузки на сервер CPU улетает в космос, а база данных рыдает в углу.
Вместо лавины данных пагинация делит их на удобные порции. Это как если бы ассистент спрашивал: «Показать следующие 10 задач?» — и давал время на их анализ. Сервер не перегружается, клиент работает шустро, а пользователь фокусируется на важном. Покажу на примере TODO-приложения, как это работает.
Вот пример API для управления проектными задачами с пагинацией, категориями и приоритетами. Код ниже — намеренно упрощен. Это не готовое решение, а иллюстрация логики. В продакшене потребуются: защита от SQL-инъекций, обработка ошибок и оптимизация подключений.
Используем Flask и SQLite, чтобы все было просто и наглядно.
from flask import Flask, jsonify, request
import sqlite3
import math
app = Flask(__name__)
# Функция для генерации списка задач project manager'а
# Использует списки возможных действий и целей, создавая 200 уникальных задач
def generate_pm_tasks():
actions = ["Составить", "Провести", "Утвердить", "Проанализировать", "Внедрить"]
targets = [
"план проекта с вехами и сроками",
"еженедельный отчет для клиента",
"риск-матрицу проекта",
"ретроспективу спринта",
"воркшоп по требованиям MVP",
"распределение ролей в команде",
"чек-лист приемки этапа",
"протокол встречи с заказчиком",
"GanttChart в MS Project",
"Change Request из-за изменений scope",
"стратегию коммуникации с командой",
"документацию в Confluence",
"Burndown Chart для отслеживания прогресса",
"резервный план на случай рисков"
]
return [f"{actions[i % len(actions)]} {targets[i % len(targets)]}" for i in range(200)]
# Функция инициализации базы данных
# Создает SQLite-базу и таблицу `tasks`, заполняет ее сгенерированными задачами
def init_db():
conn = sqlite3.connect('pm_tasks.db', check_same_thread=False)
cursor = conn.cursor()
cursor.execute('DROP TABLE IF EXISTS tasks')
cursor.execute('''
CREATE TABLE tasks (
id INTEGER PRIMARY KEY,
text TEXT,
category TEXT,
priority TEXT
)
''')
# Генерация и добавление задач в базу
tasks = generate_pm_tasks()
for idx, task in enumerate(tasks, 1):
# Определение категории задачи на основе ключевых слов
category = (
"Планирование" if any(kw in task for kw in ["план", "GanttChart", "распределение"]) else
"Коммуникация" if any(kw in task for kw in ["отчет", "встреч", "клиент"]) else
"Риски" if "риск" in task else
"Документация" if "документ" in task else
"Контроль качества"
)
# Определение приоритета задачи
priority = "Высокий" if ("риск" in task or "срок" in task) else "Средний"
cursor.execute('INSERT INTO tasks (text, category, priority) VALUES (?, ?, ?)',
(task, category, priority))
conn.commit()
conn.close()
# Корневой маршрут возвращает информацию о доступных эндпойнтах
@app.route('/')
def home():
return jsonify({
"message": "Используйте /tasks для получения задач PM",
"example": "http://localhost:8080/tasks?page=1&per_page=5",
"предупреждение": "Демо-код! Не для production."
})
# Эндпойнт для получения списка задач с пагинацией
@app.route('/tasks', methods=['GET'])
def get_tasks():
try:
# Получаем параметры `page` и `per_page`, задаем значения по умолчанию
page = int(request.args.get('page', 1))
per_page = int(request.args.get('per_page', 10))
if page < 1 or per_page < 1:
raise ValueError
except ValueError:
return jsonify({"error": "Некорректные параметры (page и per_page ≥ 1)"}), 400
# Используем параметризованные запросы
with sqlite3.connect('pm_tasks.db') as conn:
cursor = conn.cursor()
offset = (page - 1) * per_page
cursor.execute('SELECT * FROM tasks ORDER BY id LIMIT ? OFFSET ?', (per_page, offset))
tasks_data = cursor.fetchall()
# Формируем список задач
tasks = [{
"id": task[0],
"text": task[1],
"category": task[2],
"priority": task[3],
"deadline": f"2023-1{page}-{10 + idx}" # Пример динамических сроков
} for idx, task in enumerate(tasks_data, 1)]
# Пагинация
cursor.execute("SELECT COUNT(*) FROM tasks")
total_tasks = cursor.fetchone()[0]
total_pages = math.ceil(total_tasks / per_page)
base_url = request.host_url.rstrip('/') + '/tasks'
pagination = {
"current_page": page,
"total_pages": total_pages,
"total_items": total_tasks,
"next_page": f"{base_url}?page={page + 1}&per_page={per_page}" if page 1 else None
}
return jsonify({"data": tasks, "meta": pagination, "warning": "Пример для демонстрации!"})
if __name__ == '__main__':
init_db()
app.run(host='0.0.0.0', port=8080, debug=True)
Как это работает? Я хотел, чтобы мой пример с пагинацией был максимально живым и доступным даже для тех, кто впервые сталкивается с API. Replit идеально подошел для этого: здесь не нужно возиться с установкой Python, настройкой виртуального окружения или развертыванием сервера.
Этот код автоматически генерирует 200 тестовых задач, таких как «Составить план проекта» или «Провести риск-матрицу», имитируя реальные рабочие процессы. Данные сохраняются в SQLite-базу, где каждая задача классифицируется по категориям («Риски», «Планирование», «Коммуникация») и приоритетам («Высокий»/«Средний») на основе ключевых слов в тексте — например, задачи со словом «риск» попадают в категорию «Риски» и получают высокий приоритет.
Эндпоинт /tasks поддерживает пагинацию через параметры page (номер страницы) и per_page (количество задач на странице). Например, запрос GET /tasks?page=2&per_page=5 возвращает задачи 6–10. Для этого используется SQL-запрос с LIMIT и OFFSET, где OFFSET рассчитывается как (page – 1) * per_page, что позволяет серверу обрабатывать только нужный блок данных, а не всю таблицу.
Ответ API:
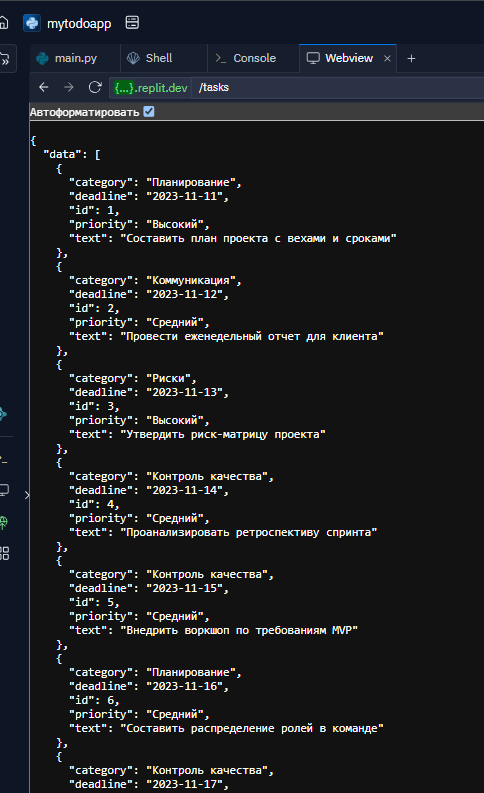
Видим, что все корректно выводится, сервер возвращает список задач с детальной информацией: категория, срок выполнения (deadline), уникальный идентификатор (id), приоритет и описание задачи (text). Каждая задача относится к определенной категории — например, «Планирование», «Риски» или «Контроль качества».
Оптимизация очевидна: если без пагинации запрос 200 задач занимал 1,5 секунды и возвращал 150 КБ данных, то с пагинацией (per_page=10) время ответа сокращается до 100 мс, а размер данных — до 3 КБ. Серверная нагрузка снижается в пять раз, а пользователь получает мгновенный отклик. Запуск прост: выполните python app.py, и сервер стартует на порту 8080.
Тестировать можно через браузер, например, перейдя по адресу: http://localhost:8080/tasks?page=3&per_page=5.
Итог: код превращает работу с тысячами задач из проблемы в удобный процесс. Пагинация убирает нагрузку с сервера, ускоряет клиент и дает пользователю контроль, а автоматическая классификация упрощает анализ данных без ручной настройки.
Как выбрать метод пагинации: три варианта за пару минут
Каждый метод имеет свои уникальные плюсы и минусы. Но несмотря на различия в реализации, цель у методов общая — эффективно дробить данные на порции. Разница лишь в том, как система находит «границы» этих порций: через смещение, временные метки или уникальные ключи. Выбор зависит от конкретных потребностей вашего приложения.
Offset-Based Pagination
Является одним из самых простых и широко используемых методов. Представьте, что вы листаете книгу, перелистывая страницы по номерам: «Страница 1», «Страница 2» и так далее. Offset-Based Pagination работает по такому же принципу: вы указываете, сколько записей пропустить (offset) и сколько показать (limit или аналог per_page).
Вот пример того, как реализовать страницу на основе “смещения” с использованием Python и Flask Framework:
from flask import Flask, request, jsonify
import math
app = Flask(__name__)
# Генерация тестовых данных
DATA = list(range(1, 101))
def paginate(data, page, per_page):
"Функция для разбивки данных на страницы."
offset = (page - 1) * per_page
return data[offset: offset + per_page]
@app.route('/items', methods=['GET'])
def get_items():
"Обработчик запроса списка элементов с пагинацией."
try:
page = int(request.args.get('page', 1))
per_page = int(request.args.get('per_page', 10))
if page < 1 or per_page < 1:
raise ValueError
paginated_data = paginate(DATA, page, per_page)
response = {
'data': paginated_data,
'page': page,
'per_page': per_page,
'total': len(DATA),
'total_pages': math.ceil(len(DATA) / per_page),
}
return jsonify(response)
except ValueError:
return jsonify({'error': 'page и per_page должны быть положительными целыми числами'}), 400
if __name__ == '__main__':
app.run(debug=True)
В этом примере клиент может запросить данные, используя параметры запроса, такие как Page и Per_page. Сервер вычисляет смещение и возвращает соответствующую порцию данных с указанием общего числа страниц.
Этот метод прост в понимании и реализации, что делает его идеальным для начинающих разработчиков. Например, Box API использует Offset-Based Pagination для обработки коллекций с фиксированной длиной.
Однако есть нюансы. Если ваши данные часто меняются, этот метод может привести к пропуску или повторению записей. Например, если вы получили первую страницу, а затем кто-то добавил новую запись, она может быть пропущена при переходе на следующую страницу. Нет защиты от «бесконечных» страниц, запрос page=1000 вернет пустой список, но это может быть «затратно» для больших баз и медленно при больших страницах.
Cursor-Based Pagination
Ну раз мы все любим читать, приведу еще пример с книгами. Представьте, что вы ставите закладку в книге на страницу 50. Даже если автор добавит новую главу, вы знаете, с какой страницы продолжить. Cursor-based Pagination работает так же: вместо номера страницы используется уникальный идентификатор или токен (например, id записи).
Пример того, как реализовать страницу на основе «курсора» с использованием Python и Flask:
from flask import Flask, request, jsonify
app = Flask(__name__)
# Исходные данные
DATA = [{'id': i, 'value': i} for i in range(1, 101)]
def get_paginated_items(cursor, per_page):
"Функция для получения подмножества данных на основе курсора."
filtered_data = [item for item in DATA if item['id'] > cursor][:per_page]
next_cursor = filtered_data[-1]['id'] if filtered_data else None
return filtered_data, next_cursor
@app.route('/items', methods=['GET'])
def fetch_items():
"Эндпоинт для получения списка элементов с пагинацией по курсору."
try:
cursor = int(request.args.get('cursor', 0))
per_page = int(request.args.get('per_page', 10))
if cursor < 0 or per_page < 1:
raise ValueError
items, next_cursor = get_paginated_items(cursor, per_page)
return jsonify({
'data': items,
'cursor': cursor,
'next_cursor': next_cursor,
'per_page': per_page,
'total': len(DATA),
})
except ValueError:
return jsonify({'error': 'cursor должен быть неотрицательным, а per_page — положительным целым числом'}), 400
if __name__ == '__main__':
app.run(debug=True)
В этом примере клиент может запросить данные, используя параметры запроса, такие как cursor и per_page. Сервер возвращает лицензионные данные вместе со следующим курсором, который будет использоваться в следующем запросе.
Этот метод идеален для социальных сетей и чатов, поскольку сохраняет порядок и целостность данных даже при добавлении или удалении записей. Однако он требует уникального идентификатора для каждого элемента, что может усложнить реализацию, особенно для больших наборов данных. Еще из минусов: есть зависимость от сортировки. Cursor работает только при жесткой сортировке данных (например, ORDER BY id). Если сортировка меняется, cursor теряет актуальность. И проблемы с повторяющимися значениями: если несколько записей имеют одинаковый id или timestamp, cursor может вернуть дубликаты или «пропустить» элементы.
Keyset Pagination
Также известная как «метод поиска», или пагинация с токеном продолжения. Это альтернатива пагинации на основе offset. Она работает примерно как курсорная, но использует комбинацию ключей (например, нескольких столбцов в базе данных) для определения начальной точки каждой страницы. Это как перематывать видео по времени: если вы остановились на 1:20, следующий раз начнете с 1:21.
Реализация страницы keyset с использованием Python и Flask:
from flask import Flask, request, jsonify
app = Flask(__name__)
# Генерация тестовых данных
DATA = [{'id': i, 'timestamp': i * 10, 'value': i} for i in range(1, 101)]
def filter_items(last_id, last_timestamp, per_page):
"Фильтрует и возвращает список элементов на основе last_id и last_timestamp."
filtered = [item for item in DATA if (item['timestamp'], item['id']) > (last_timestamp, last_id)]
return filtered[:per_page], filtered[-1] if filtered else None
@app.route('/items', methods=['GET'])
def fetch_items():
"Эндпоинт для получения списка элементов с пагинацией."
try:
last_id = int(request.args.get('last_id', 0))
last_timestamp = int(request.args.get('last_timestamp', 0))
per_page = int(request.args.get('per_page', 10))
if last_id < 0 or last_timestamp < 0 or per_page < 1:
raise ValueError
items, next_item = filter_items(last_id, last_timestamp, per_page)
return jsonify({
'data': items,
'last_id': last_id,
'last_timestamp': last_timestamp,
'next_id': next_item['id'] if next_item else None,
'next_timestamp': next_item['timestamp'] if next_item else None,
'per_page': per_page,
'total': len(DATA),
})
except ValueError:
return jsonify({'error': 'last_id и last_timestamp должны быть неотрицательными, per_page — положительным'}), 400
if __name__ == '__main__':
app.run(debug=True)
В этом примере клиент может запросить данные, используя параметры запроса, такие как Fast_id, Last_timestamp и Per_page. Сервер возвращает лицензионные данные вместе со следующим идентификатором и временной меткой, которая будет использоваться в последующих запросах.
Этот метод чрезвычайно эффективен для обработки огромных объемов данных, поскольку использует индексированные поля. Например, GitLab Docs подтверждает использование keyset pagination для эффективной обработки данных.
Однако для эффективной работы необходимо иметь четко определенный порядок сортировки данных, что может быть сложно реализовать в некоторых случаях. А еще если сортировочное поле не уникально (например, несколько записей имеют одинаковый created_at), keyset может вернуть дубликаты или «пропустить» элементы.
Пагинация как стратегия: от техники к бизнесу
С точки зрения технических специалистов пагинация решает проблемы производительности и устойчивости систем. Например, платформа Netflix обслуживает более 200 миллионов подписчиков по всему миру. Без пагинации обработка запросов с огромными наборами данных (например, каталоги фильмов или рекомендации) привела бы к коллапсу серверов. Вместо этого компания использует Cursor-based Pagination для эффективной обработки ленты контента, что позволяет поддерживать стабильную работу системы даже при пиковых нагрузках.
Однако важность пагинации выходит за рамки только оптимизации запросов. Она также помогает защитить API от DDoS-атак. Когда клиент может запрашивать данные без ограничений, злоумышленники могут использовать это для создания чрезмерной нагрузки на сервер. Пагинация позволяет установить пределы (limit и page) и минимизировать риск перегрузки системы. Эти практики описаны в рекомендациях OWASP для защиты от Slow DDoS-атак.
Кроме того, пагинация обеспечивает масштабируемость. GitLab, например, применяет keyset Pagination для управления миллионами коммитов в своих репозиториях. Это позволяет им сохранять высокую производительность, даже когда объем данных увеличивается. Благодаря такой стратегии GitLab избежал необходимости существенного расширения своей инфраструктуры, сохранив при этом качество работы сервиса.
С точки зрения бизнеса пагинация напрямую влияет на пользовательский опыт (UX) и показатели конверсии. Так, Etsy, крупнейшая онлайн-площадка для хендмейд-продуктов, перешла на Cursor-based Pagination для своей ленты товаров. Это позволило сократить время загрузки на 70%, что повысило конверсию на 15%. Ускоренная работа сайта сделала взаимодействие с платформой более комфортным для пользователей, что положительно сказалось на продажах.
Что в итоге
Выбор метода должен соответствовать сценарию. Cursor pagination подходит для динамичных данных. Offset pagination лучше использовать для статичных наборов. Всегда важно учитывать компромиссы между удобством и производительностью. Граничные случаи и нагрузочные тесты требуют особого внимания. Даже если пагинация работает на небольших данных, на больших объемах она может превратиться в узкое место. Важно заранее понимать, как запросы поведут себя под нагрузкой.
И помните: пагинация не является временным костылем. Это часть архитектуры системы, влияющая на быстродействие и UX. Грамотный подход делает сервис устойчивым и готовым к масштабированию.
С ростом объемов данных и усложнением архитектур систем — например, микросервисов и serverless-решений — пагинация будет играть все более важную роль. Мы видим тенденцию к переходу от простых методов (offset) к более продвинутым (cursor и keyset), особенно в проектах с высокой динамикой данных. В будущем разработчики будут все чаще использовать комбинированные подходы: например, Cursor — для клиентской части, а keyset — для внутренних сервисов.
Кроме того, появление новых технологий, таких как GraphQL и стриминговые протоколы, может изменить подход к пагинации. Например, вместо классической пагинации мы можем увидеть больше решений на основе бесконечной загрузки. Тем не менее, классические методы пагинации останутся актуальными для REST API и баз данных, где предсказуемость и контроль над запросами имеют решающее значение.





