

Проблема традиционных реляционных баз данных в том, что они не всегда справляются с обработкой огромных объемов информации. Вот вам нужно быстро найти, проиндексировать и проанализировать логи, события или метрики, но вы упираетесь в ограничения масштабируемости, автошардирования и скорости обработки запросов специфического профиля нагрузки. Знакомо?
Что такое OpenSearch
OpenSearch 2.18 (Latest) — это open source высокопроизводительная поисковая система и аналитический движок. Инструмент позволяет индексировать и анализировать большие объемы данных в режиме реального времени. Это форк Elasticsearch 7.10, разработанный Amazon после смены лицензии Elastic на проприетарную. OpenSearch сохраняет совместимость с API Elasticsearch, но при этом остается полностью открытым и свободным для использования. Это делает его удобным решением для пользователей, ищущих open source альтернативу.
OpenSearch хорош тем, что предлагает полнотекстовый поиск по индексированным данным, включая поддержку морфологии и сложных поисковых запросов. Помимо тривиального поиска можно также анализировать логи. А чтобы наглядно представить данные, можно строить таблицы и графики с помощью OpenSearch Dashboards. Отдельно отмечу поддержку машинного обучения — можно автоматически выявлять аномалии в данных за счет поддержки таких плагинов, как anomaly-detection и opensearch-ml.
Наконец, благодаря open source модели и плагинам OpenSearch можно адаптировать под разные задачи. Например, плагин notifications предназначен для управления уведомлениями через интеграции с менеджерами или веб-хуками с POST-, PUT- и PATH-запросами.
Отличия OpenSearch от Elasticsearch
OpenSearch стал основной альтернативой ELK, предлагая:
- полностью открытую лицензию (Apache 2.0), что позволяет использовать и модифицировать продукт без ограничений;
- дополнительные функции и плагины от сообщества без лицензий и платных ограничений;
- совместимость с API Elasticsearch для упрощения миграции с Elasticsearch;
- поддержку сообщества и развитие в концепции AWS-like, но без привязки к конкретному облачному провайдеру.
Итак, что мы имеем? С одной стороны, OpenSearch — отличный выбор для разработчиков, аналитиков и DevOps-инженеров, которым необходим мощный инструмент для работы с большими текстовыми данными. С другой, платформа требовательна к железу и сложна в эксплуатации.
OpenSearch as a Service в Selectel
Чтобы упростить повседневную жизни DevOp- и SRE-инженеров, дата-аналитиков и разработчиков, мы выпустили новую услугу OpenSearch как сервис. Это полностью управляемая платформа, которая позволяет развернуть кластеры OpenSearch за несколько минут. Самостоятельного администрировать инфраструктурную составляющую при этом не нужно.
В услугу входит:
- установка и настройка нод,
- формирование групп в кластере,
- масштабирование, репликация, шардирование и отказоустойчивость,
- мониторинг и резервное копирование,
- обеспечение хранения данных в соответствии с требованиями ИБ: 152-ФЗ, ГОСТ 57580 и прочих,
- интеграция с другими сервисами Selectel.
В целом, мы взяли на себя всю инфраструктурную рутину вроде настройки и поддержки сложных многосоставных систем. При этом работа на уровне приложения OpenSearch остается в зоне ответственности клиента.
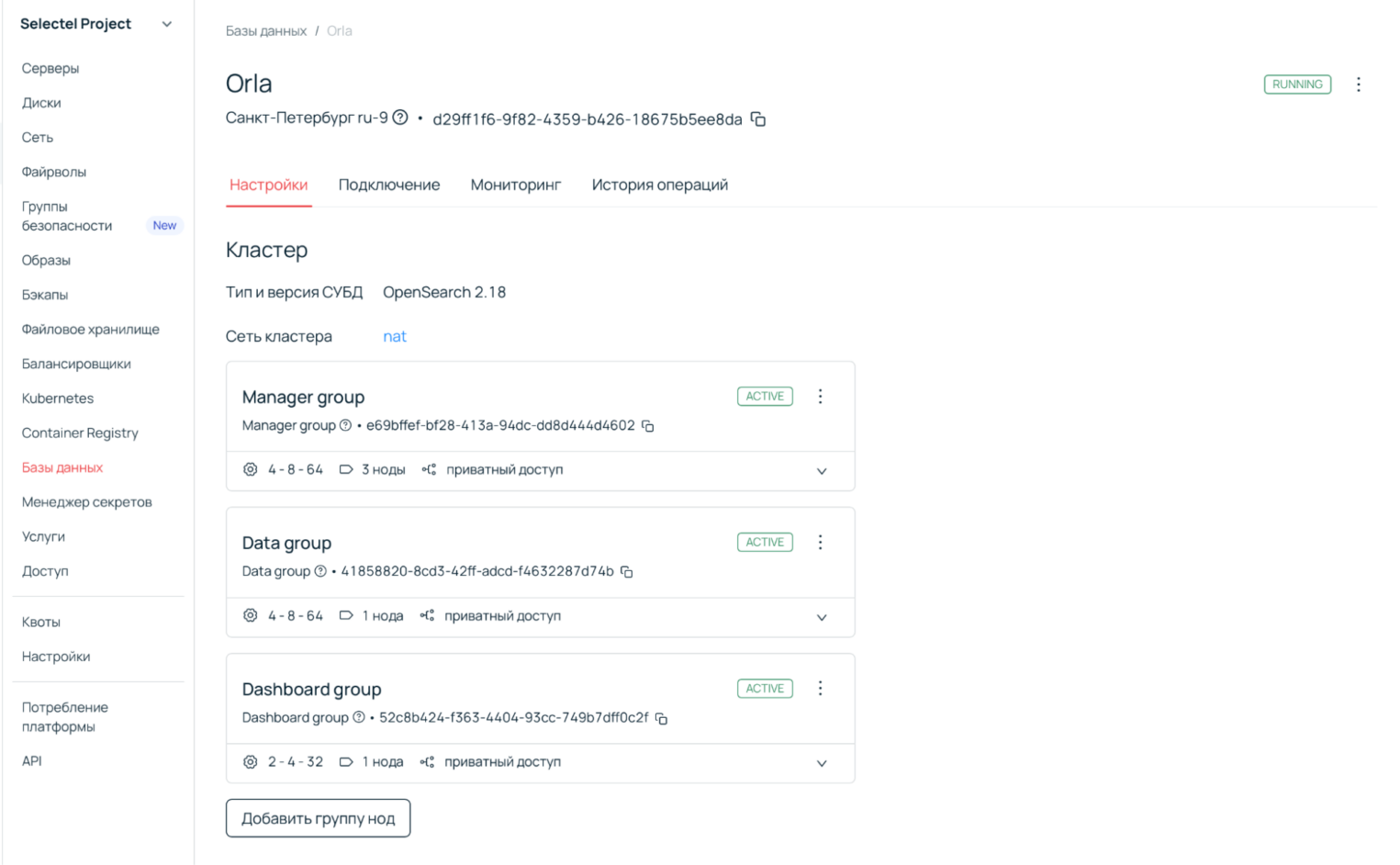
Про группы нод и роли в нашей услуге
Кластер OpenSearch состоит из четырех групп:
- три ноды менеджеров,
- дашборды,
- первая группа датанод, до 10 штук (например, для горячего хранения),
- вторая группа датанод, до 10 штук (например, для холодного хранения).
Рассмотрим каждую группу отдельно.
Подробное описание того, как все устроено под капотом — тема для отдельной статьи. А пока тезисно перечислю, что делает каждая группа нод.
Ноды-менеджеры
Это обязательная к использованию группа, которая отвечает за управление, координацию и работоспособность кластера, а также за балансировку нагрузки. Вот что конкретно делает группа:
- управляет состоянием кластера: поддерживает и распространяет метаданные о состоянии всех узлов, отслеживает добавления/удаления узлов и своевременное обновление состояния кластера, управляет индексами, включая их создание, удаление и обновление;
- распределяет данные и задачи: контролирует распределение шардов (фрагментов индексов) между узлами кластера, перераспределяет их в случае выхода узла из строя или его добавления;
- обеспечивает отказоустойчивость: автоматически обнаруживает отказы узлов и инициирует процедуры восстановления, координируют репликацию данных;
- распределяет нагрузку: анализирует и обеспечивает равномерную обработку запросов и операций записи;
- обрабатывает операции управления: выполняет административные операции (создание индексов, управление настройками, закрытие/открытие индексов), реализует обновления и миграции без прерывания работы кластера;
- координирует выбор Master Election: в кластерах с несколькими менеджерами один из них выбирается в качестве основного (Master node) и выполняет критические задачи, включая принятие решений о распределении шард и управление метаданными. Группа менеджеров координирует выбор нового мастера в случае сбоя текущего.
выполняет мониторинг и сбор метрик: собирает данные о состоянии кластера и предоставляет их для анализа и диагностики, например, в OpenSearch Dashboards.
Дашборды
Это опциональная к использованию группа в кластере. Она отвечает за предоставление веб-интерфейса визуализации данных и управление кластером через веб-панель. Эти узлы оптимизированы для обработки запросов пользователей и выполнения задач, связанных с аналитикой и визуализацией.
Основные задачи группы дашбордов:
- визуализация данных и мониторинга состояния кластера,
- обработка пользовательских и аналитических запросов,
- управление виджетами и дашбордами,
- реализация веб-интерфейса для администрирования: управления пользователями, резервного копирования и т .д.
Дашборды не участвуют непосредственно в обработке данных, управлении шард-распределением или кластеризацией, поэтому их использование опционально и призвано просто упростить пользователю работу с OpenSearch API.
Группа датанод, или Data Nodes
Это основной компонент кластера, который выполняет ключевые задачи, связанные с индексированием, шардированием, репликацией и обработкой запросов. В кластере OpenSearch группа датанод отвечает за хранение, управление и обработку данных. Рассмотрим ее задачи подробнее.
- Хранение данных: хранение индексов и шардов, управление репликами, оптимизация хранения данных.
- Обработка запросов: выполнение операций чтения и записи, индексирование новых данных, распределение их по соответствующим шард-узлам.
- Репликация данных: управление репликами шардов, перенаправление запросов на реплики при недоступности основной копии.
- Обеспечение отказоустойчивости: автоматическое восстановление данных из реплик при сбое узла, обновление состояния кластера.
Взаимодействие с мастер-нодами: получение инструкций от нод менеджеров по размещению и управлению шард-репликами, передача информации о состоянии данных и шардов для поддержания актуального состояния кластера.
Для промышленного использования важно следить за состоянием датанод, включая использование CPU, памяти и дискового пространства, чтобы избежать перегрузки или снижения производительности.
Как начать использовать OpenSearch в Selectel
Мы постарались сделать так, чтобы использование нашей услуги было максимально простым. Чтобы приступить к работе с OpenSearch, выполните несколько шагов.
- Зайдите в панель управления и перейдите в раздел Продукты → Облачные базы данных.
2. Выберите подходящие вам регион и пул.
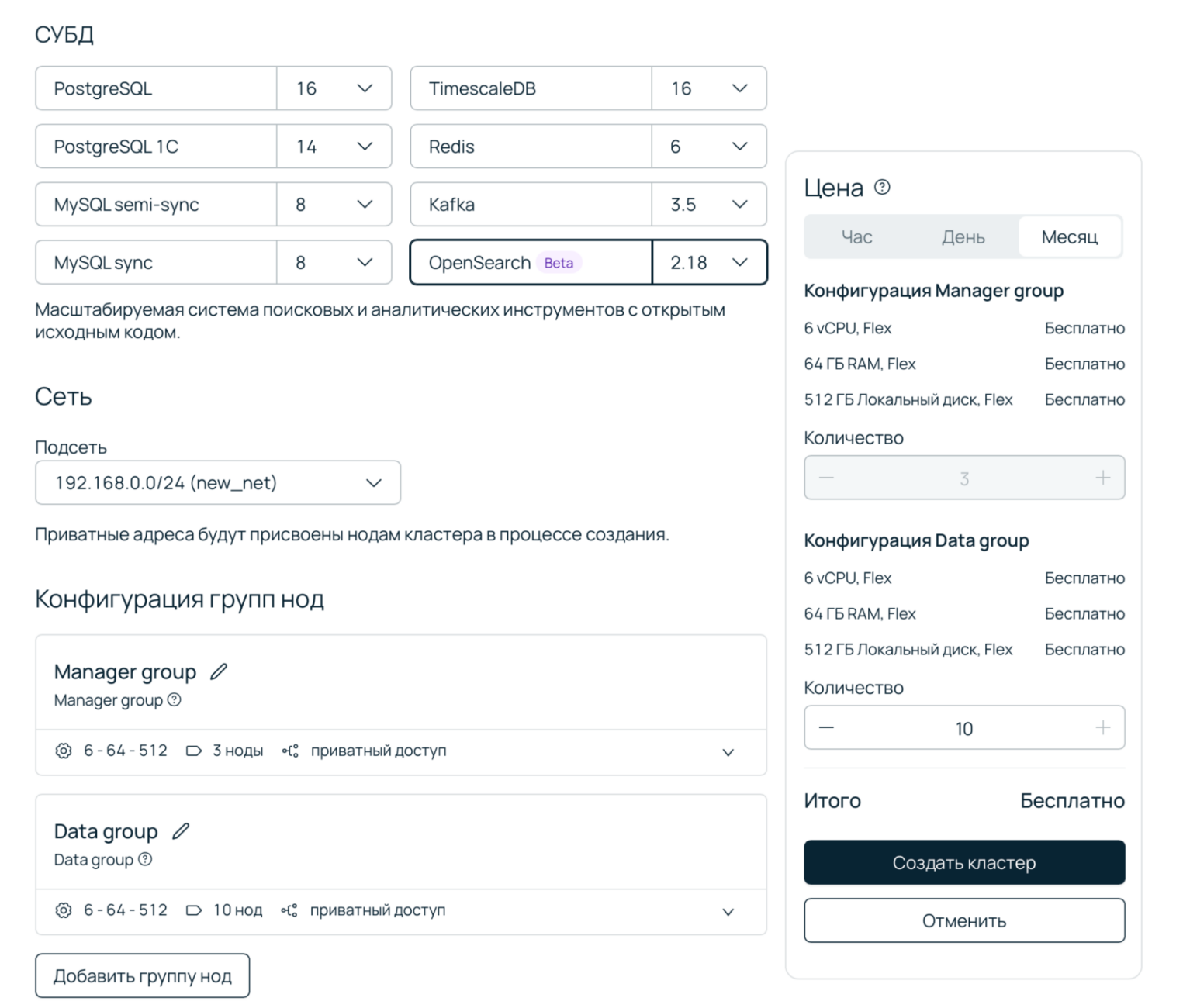
3. В разделе СУБД выберите OpenSearch.
4. Выберите приватную сеть или создайте новую. Опциональный шаг: выберите группу нод, в которой будете использовать публичные адреса.
5. Выберите конфигурацию для каждой группы нод. Все ноды внутри этой группы будут иметь одинаковую конфигурацию.
6. Затем нажмите Создать кластер.
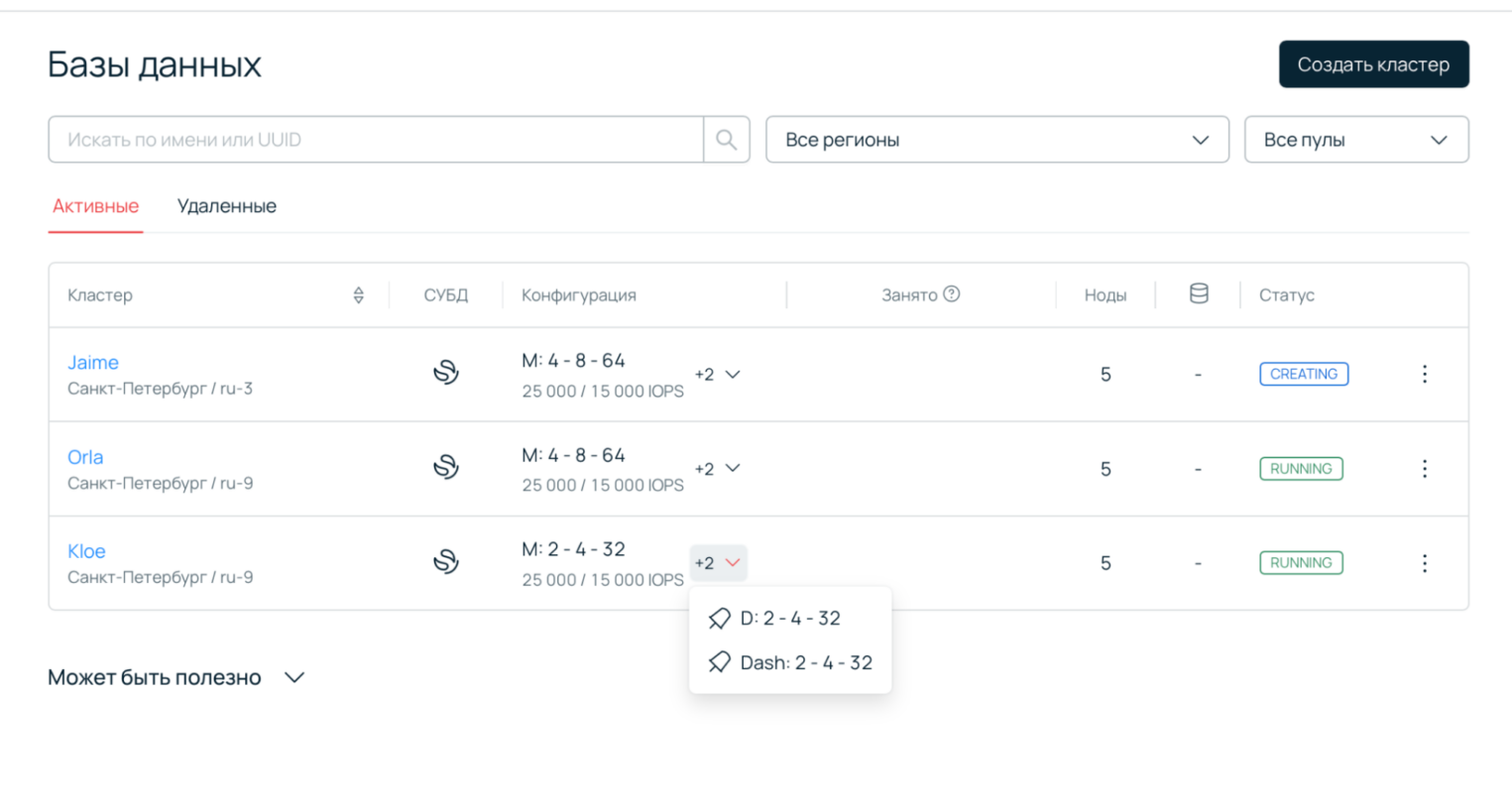
7. Подключите источники данных и настройте индексирование логов, используя OpenSearch API.
8. Визуализируйте данные в OpenSearch Dashboard.
Как использовать OpenSearch с Python
В нашем тривиальном примере будем использовать библиотеку opensearch-py. Вот пример кода для индексации и поиска данных:
from opensearchpy import OpenSearch
host = 'your-opensearch-endpoint'
port = 9200
auth = ('user', 'password')
client = OpenSearch(
hosts=[{'host': host, 'port': port}],
http_auth=auth,
use_ssl=True,
verify_certs=False
)
# Создание индекса
index_name = "logs"
client.indices.create(index=index_name, ignore=400)
# Добавление документа
doc = {"message": "Ошибка в системе", "timestamp": "2025-02-10T12:00:00"}
client.index(index=index_name, body=doc)
# Поиск по индексу
query = {"query": {"match": {"message": "Ошибка"}}}
response = client.search(index=index_name, body=query)
print(response)
Этот код демонстрирует, как подключиться к кластеру OpenSearch, создать индекс, добавить документ и выполнить поиск.
В ближайшее время мы планируем интегрировать OpenSearch с другими сервисами Selectel, добавить поддержку HighFreq и Dedicated аппаратных платформ и новых функций.





