Объединение проектов в разных дата-центрах


Обычная L2 схема
По мере роста IT-инфраструктуры в дата-центре у клиентов возникает необходимость объединять серверы, СХД, файерволы в единую сеть. Для этого Selectel изначально предлагает использовать локальную сеть.
Локальная сеть устроена как классическая «кампусная» сеть в пределах одного дата-центра, только вот коммутаторы доступа расположены непосредственно в стойках с серверами. Коммутаторы доступа далее объединены в один коммутатор уровня агрегации. Каждый клиент может заказать подключение к локальной сети для любого устройства, которое он арендует или размещает у нас в дата-центре.
Для организации локальной сети используются выделенные коммутаторы доступа и агрегации, так что проблемы в интернет-сети не затрагивают локальную сеть.
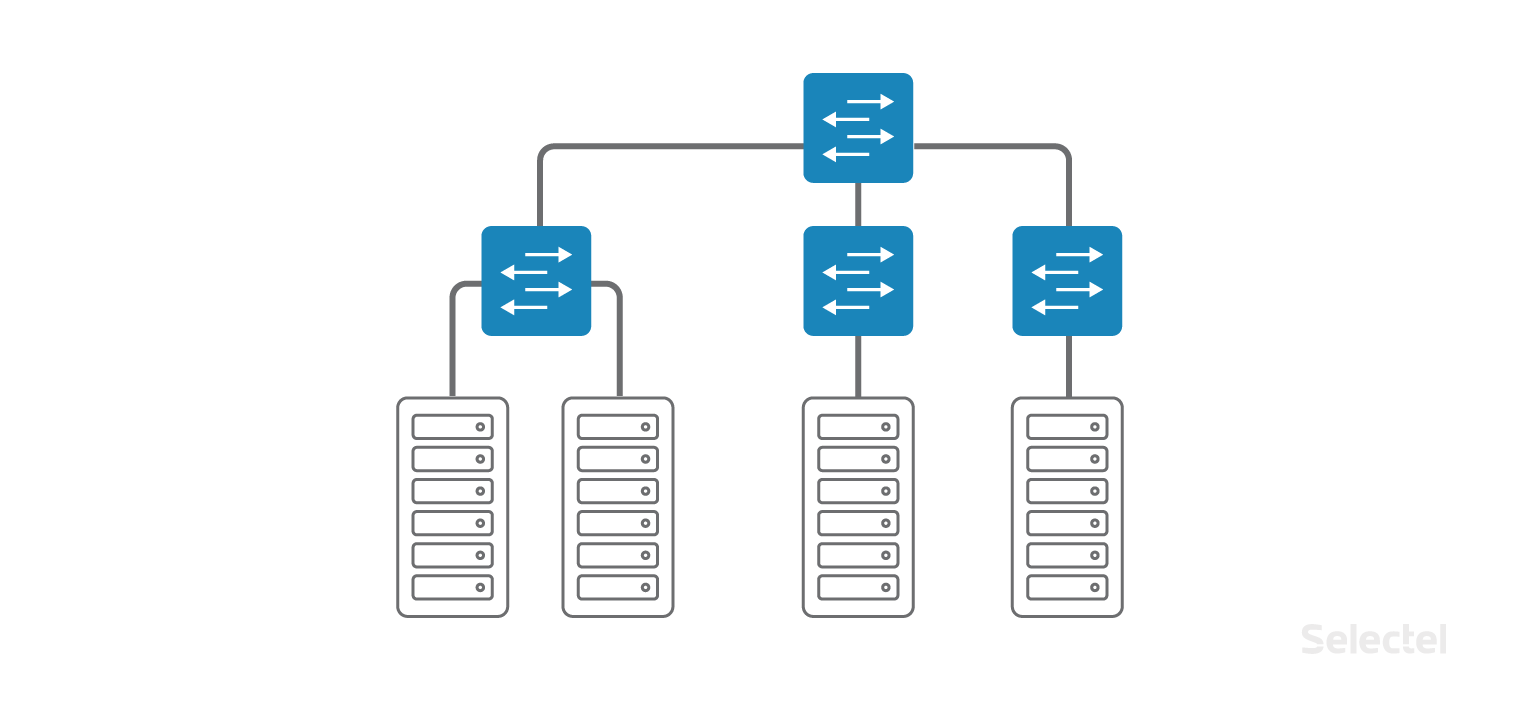
Неважно, в какой стойке стоит очередной сервер — Selectel объединяет серверы в единую локальную сеть, и не надо думать о коммутаторах или местоположении сервера. Вы можете заказать сервер тогда, когда он будет нужен, и он будет подключен к локальной сети.
L2 прекрасно работает, пока размер дата-центра невелик, когда заполнены не все стойки. Но по мере увеличения количества стоек, серверов в стойках, коммутаторов, клиентов — схема становится существенно сложнее в обслуживании.
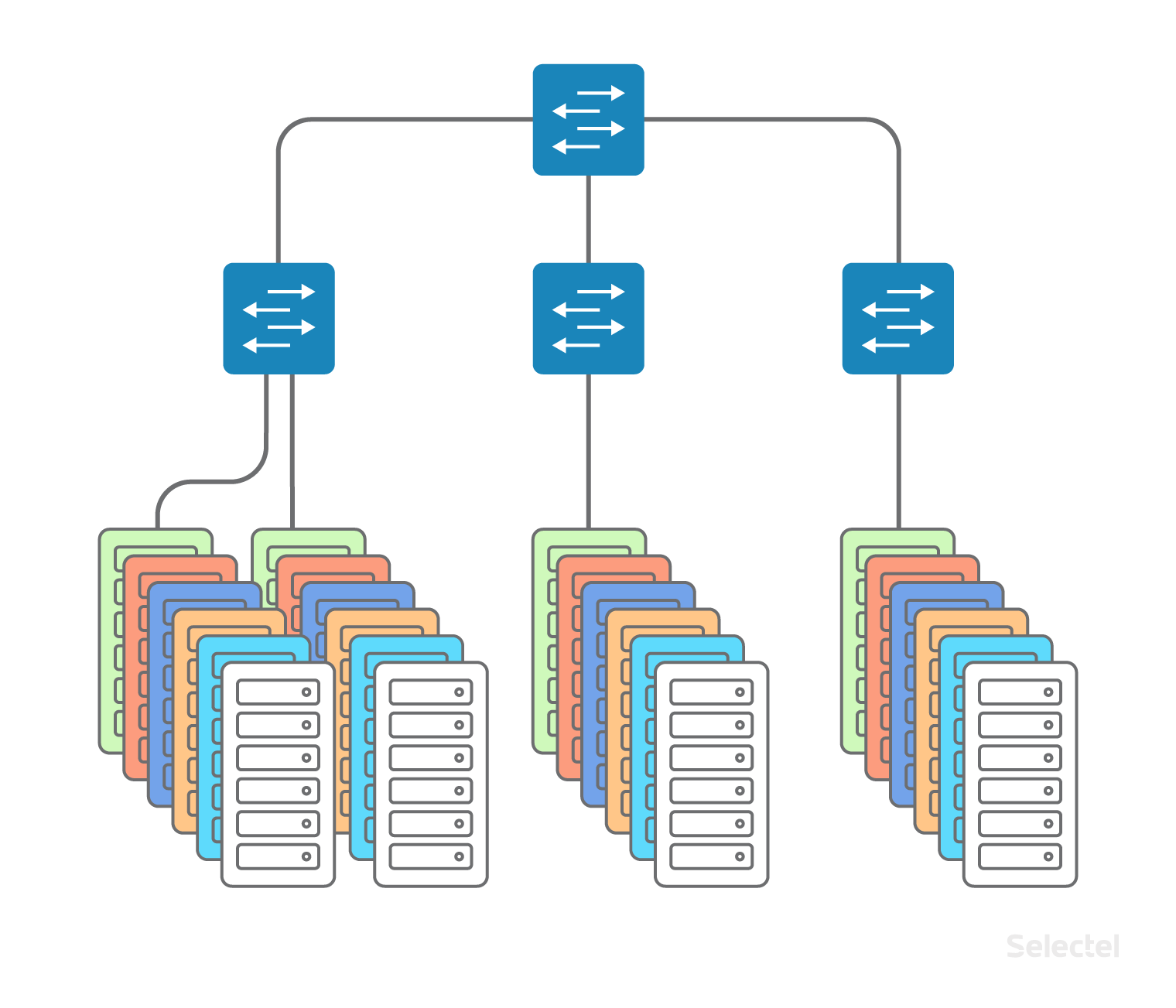
Серверы одного клиента могут размещаться в нескольких дата-центрах для обеспечения катастрофоустойчивости или при невозможности разместить сервер в уже имеющемся дата-центре (например, заняты все стойки и все места). Между несколькими дата-центрами также необходима связность — между серверами по локальной сети.
По мере роста количества дата-центров, стоек, серверов схема все более усложняется. Сначала связность между серверами разных дата-центров осуществлялась просто на уровне коммутаторов агрегации с использованием технологии VLAN.
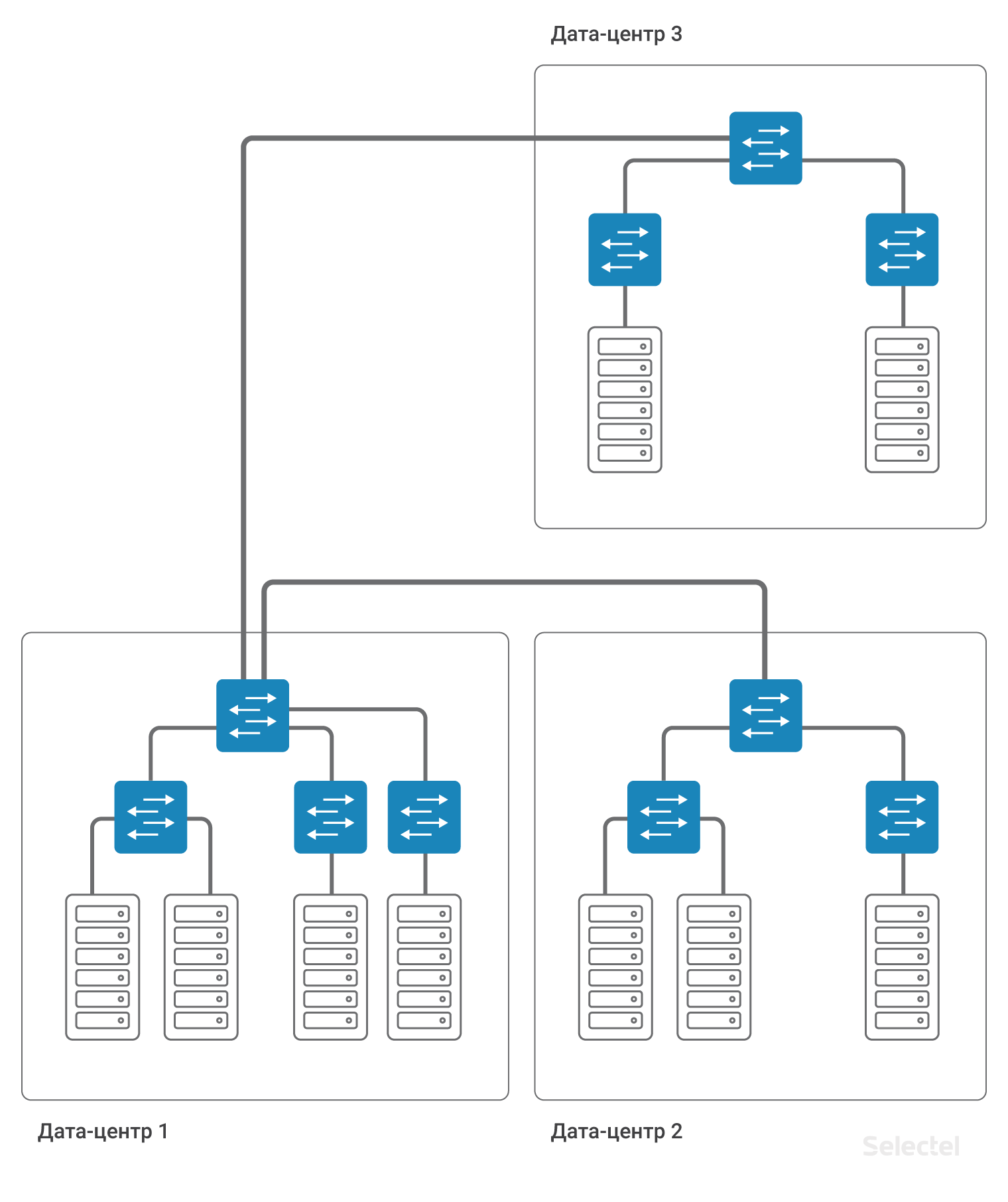
Но идентификационное пространство VLAN весьма ограничено (4095 VLAN ID). Так что для каждого дата-центра приходится использовать свой набор VLAN, что сокращает количество возможных идентификаторов, которые можно использовать между дата-центрами.
Проблемы L2
При использовании схемы на уровне L2 с использованием VLAN некорректная работа одного из серверов в дата-центре может привести к перебоям в предоставлении услуги по другим серверам. Из наиболее частых проблем можно отметить:
- Проблемы с STP (Spanning-Tree Protocol)
- Проблемы с широковещательными штормами (Broadcast Storm)
- Проблемы с некорректной обработкой мультикаста
- Человеческий фактор (перенос линков, перенос VLAN)
- Проблемы с организацией резервирования по L2
- Проблемы с unknown-unicast трафиком
- Проблемы с количеством МАС-адресов
Проблемы с STP зачастую касаются в том числе и настроек клиентских серверов или клиентского оборудования. В отличие от популярных точек обмена трафиком, мы не можем полностью фильтровать STP на портах доступа и гасить порты при поступлении STP PDU. На STP у ряда производителей сетевого оборудования реализуется такой базовый функционал коммутаторов дата-центра, как обнаружение петель в сети.
При некорректной работе с STP со стороны клиентского оборудования может быть затронут весь STP-домен как минимум одного коммутатора доступа. Использование расширений протокола STP, таких как MSTP, также не является решением, поскольку количество портов, VLAN, коммутаторов зачастую превышает архитектурные возможности масштабирования протокола STP.
Broadcast
Сеть в дата-центре может быть построена на устройствах разных производителей. Порой достаточно даже отличий в версии ПО коммутаторов, чтобы коммутаторы по-разному обрабатывали STP. Так, например, в дата-центре «Дубровка 3» расположено 280 стоек, что превышает максимально возможное количество коммутаторов в одном STP-домене.
При широком использовании STP в такой сети время реакции на любые изменения, в частности, простое включение или выключение порта, будет превышать все пороги ожидания. Вы же не хотите, чтобы при включении порта одним из клиентов, у вас пропадала связность по сети на несколько минут?
Проблемы с broadcast-трафиком часто возникают как по причине неверных действий на сервере (например, создание одного bridge между несколькими портами сервера), так и из-за неправильной настройки ПО на серверах. Мы стараемся нивелировать возможные проблемы с количеством broadcast-трафика, попадающего к нам в сеть. Но мы это можем делать на одном порту подключения сервера, а если в один коммутатор включено 5 серверов, каждый из которых не превышает установленные пороги, то вместе они могут сгенерировать достаточно трафика, чтобы сработал уже контроль на коммутаторе агрегации. Из собственной практики, проблемы с широковещательным штормом со стороны сервера могут быть вызваны специфическим выходом из строя сетевой карты сервера.
Защищая сеть целиком, коммутатор агрегации «положит» порт, на котором произошла сетевая аномалия. К сожалению, это приведет к неработоспособности как пяти серверов, из-за которых произошел данный инцидент, так и к неработоспособности других серверов (вплоть до нескольких стоек в дата-центре).
Multicast
Проблемы с некорректной обработкой multicast-трафика — очень специфичные проблемы, возникающие в комплексе из-за некорректной работы ПО на сервере и ПО на коммутаторе. Например, между несколькими серверами настроен Corosync в multicast-режиме. Штатно обмен Hello-пакетами осуществляется небольшими объемами. Но в ряде случаев серверы с установленным Corosync могут пересылать достаточно много пакетов. Этот объем уже требует или специальной настройки коммутаторов, или использования корректных механизмов обработки (IGMP join и другие). При неправильном срабатывании механизмов или при срабатывании порогов могут быть перерывы сервиса, которые затронут других клиентов. Конечно, чем меньше клиентов на коммутаторе, тем меньше вероятность возникновения проблем от другого клиента.
Человеческий фактор — довольно непредвиденный вид проблем, который может возникнуть при работе с сетевым оборудованием. Когда сетевой администратор один, и он грамотно строит свою работу, документирует действия и обдумывает последствия своих действий, то вероятность возникновения ошибки довольно мала. Но когда растет количество оборудования, находящегося в эксплуатации дата-центра, когда сотрудников становится много, когда становится много задач — тогда требуется совершенно другой подход к организации работы.
Некоторые виды типовых действий во избежание человеческой ошибки автоматизированы, но многие виды действий на текущий момент нельзя автоматизировать, или цена автоматизации таких действий неоправданно высока. Например, физическое переключение патч-кордов на патч-панели, подключение новых линков, замена существующих линков. Все, что связано с физическим контактом с СКС. Да, есть патч-панели, позволяющие выполнять коммутацию удаленно, но они очень дорогие, требуют большого объема подготовительных работ и очень ограничены в своих возможностях.
Никакая автоматическая патч-панель не проложит новый кабель, если он потребуется. Ошибиться можно и при настройке коммутатора или маршрутизатора. Указать неправильный номер порта, номер VLAN, опечататься при вводе числового значения. При указании каких-то дополнительных настроек не учесть их влияние на существующую конфигурацию. При увеличении сложности схемы, усложнении схемы резервирования (например, по причине достижения текущей схемой предела масштабирования) вероятность человеческих ошибок возрастает. Человеческая ошибка может быть у любого, независимо от того, что за устройство находится в стадии конфигурирования, сервер, коммутатор, маршрутизатор или какое-то транзитное устройство.
Организация резервирования по L2, на первый взгляд, кажется простой задачей для небольших сетей. В курсе Cisco ICND проходят основы использования STP в качестве протокола, как раз изначально предназначенного для организации резервирования по L2. STP имеет массу ограничений, которые в этом протоколе, что называется, «by design». Надо не забывать, что любой STP-домен имеет очень ограниченную «ширину», то есть количество устройств в одном STP-домене, довольно мало по сравнению с количеством стоек в дата-центре. Протокол STP в своей изначальной версии разделяет линки на используемый и резервный, что не обеспечивает полной утилизации аплинков при нормальной эксплуатации.
Использование других протоколов резервирования по L2 налагает свои ограничения. Например, ERPS (Ethernet Ring Protection Switching) — на используемую физическую топологию, на количество колец на одном устройстве, на утилизацию всех линков. Использование других протоколов, как правило, сопряжено с проприетарными изменениями у разных производителей или ограничивает построение сети одной выбранной технологией (например, TRILL/SPBm-фабрика при использовании оборудования Avaya).
Unknown-unicast
Особо хочется выделить подтип проблем с unknown-unicast трафиком. Что это такое? Трафик, который по L3 предназначен на какой-то конкретный IP-адрес, но по L2 широковещается в сети, то есть, передается на все порты, принадлежащие данному VLAN. Данная ситуация может возникать по ряду причин, например, при получении DDoS на незанятый IP-адрес. Или если при опечатке в конфигурации сервера был указан несуществующий в сети адрес в качестве резервного, а на сервере исторически существует статическая ARP-запись по этому адресу. Unknown-unicast появляется в случаях наличия всех записей в ARP-таблицах, но при отсутствии МАС-адреса получателя в таблицах коммутации транзитных коммутаторов.
Например, порт, за которым расположен сетевой хост с данным адресом, очень часто переходит в выключенное состояние. Подобный вид трафика лимитируется транзитными коммутаторами и обслуживается зачастую так же, как и broadcast или multicast. Но в отличие от них, unknown-unicast трафик может быть инициирован «из интернета», а не только из сети клиента. Особенно велик риск возникновения unknown-unicast трафика в случаях, когда правила фильтрации на пограничных маршрутизаторах позволяют подмену IP-адресов снаружи.
Даже само количество МАС-адресов может иногда быть проблемой. Казалось бы, при размере дата-центра в 200 стоек, по 40 серверов в стойке, вряд ли количество МАС-адресов сильно превысит количество серверов в дата-центре. Но это уже не соответствующее действительности утверждение, так как на серверах может быть запущена одна из систем виртуализации, и каждая виртуальная машина может быть представлена своим МАС-адресом, а то и несколькими (при эмуляции нескольких сетевых карт на виртуальной машине, например). Итого мы можем получить с одной стойки в 40 серверов больше нескольких тысяч легитимных МАС-адресов.
Такое количество МАС-адресов может повлиять на заполненность таблицы коммутации на некоторых моделях коммутаторов. Кроме того, для определенных моделей коммутаторов при заполнении таблицы коммутации применяется хеширование, и какие-то МАС-адреса могут вызвать хеш-коллизии, ведущие к появлению unknown-unicast трафика. Случайный перебор МАС-адресов на арендованном сервере со скоростью, скажем, 4,000 адресов в секунду, может вызвать переполнение таблицы коммутации на коммутаторе доступа. Естественно, на коммутаторах применяются ограничения по количеству МАС-адресов, которые могут быть изучены на портах коммутатора, но в зависимости от конкретной реализации данного механизма, данные могут трактоваться по-разному.
Опять же, отправка трафика на МАС-адрес, зафильтрованный данным механизмом, ведет к появлению unknown-unicast трафика. Самое неприятное в данной ситуации, что коммутаторы редко тестируются у производителя на самовосстановление после случаев с переполнением таблицы коммутации. Разовое переполнение таблицы, вызванное, скажем, ошибкой одного клиента в параметрах hping или в написании скрипта, обеспечивающего мониторинг его инфраструктуры, может вести к перезагрузке коммутатора и перерыву связи для всех серверов, расположенных в стойке. Если же такое переполнение случается на коммутаторе уровня агрегации, то перезагрузка коммутатора может привести к 15-минутному простою всей локальной сети дата-центра.
Хочется донести, что использование L2 оправдано только для ограниченных случаев и накладывает много ограничений. Размер сегмента, количество L2 сегментов — это все параметры, которые необходимо оценивать каждый раз при добавлении нового VLAN с L2 связностью. И чем меньше L2 сегментов, тем проще и, как следствие, надежнее сеть в обслуживании.
Типовые случаи использования L2
Как уже упоминалось, при постепенном развитии инфраструктуры в одном дата-центре используется L2 локальная сеть. К сожалению, это использование подразумевается и при развитии проектов в другом дата-центре или в другой технологии (например, виртуальные машины в облаке).
Связь front и back-end, резервное копирование
Как правило, использование локальной сети начинается с разделения функционала front и back-end сервисов, выделения СУБД на отдельный сервер (для повышения производительности, для разделения типа ОС на сервере приложений и СУБД). Поначалу использование L2 для данных целей выглядит оправданным, в сегменте всего несколько серверов, часто они даже расположены в одной стойке.
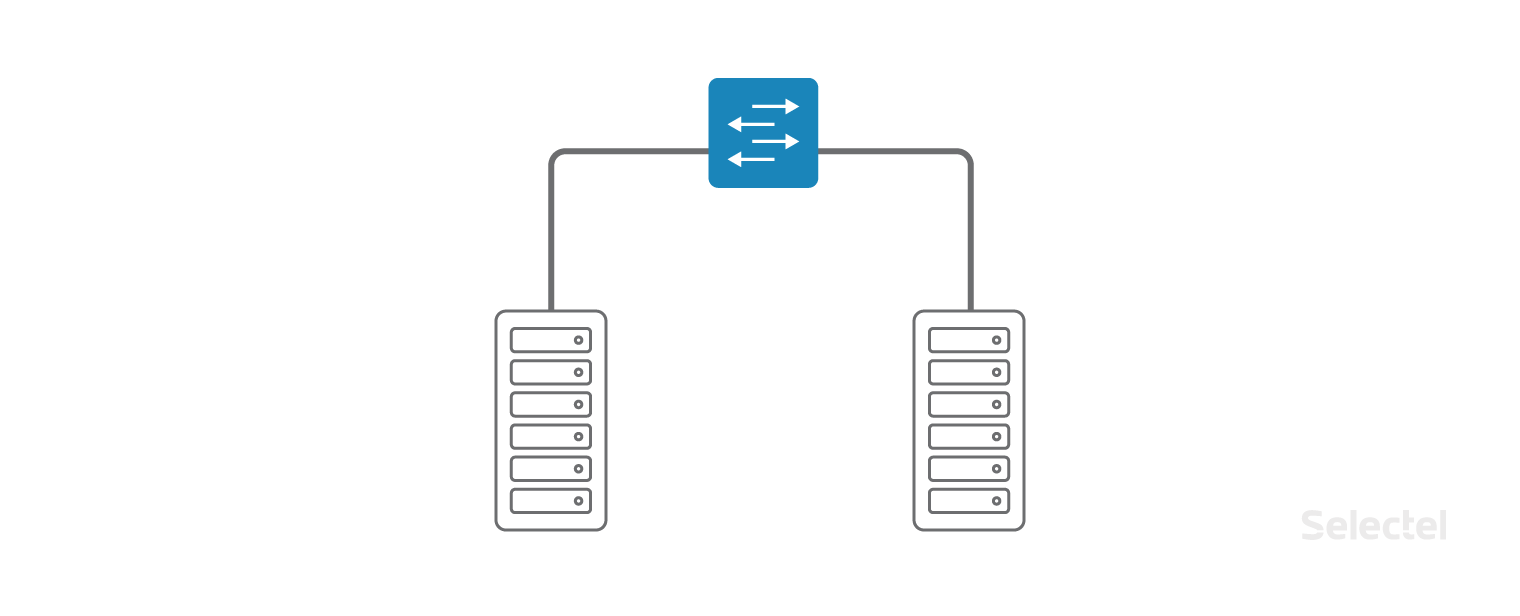
Серверы включаются в один VLAN, в один или несколько коммутаторов. По мере увеличения количества оборудования, все новые и новые серверы включаются в коммутаторы новых стоек в дата-центре, от чего L2-домен начинает расти в ширину.
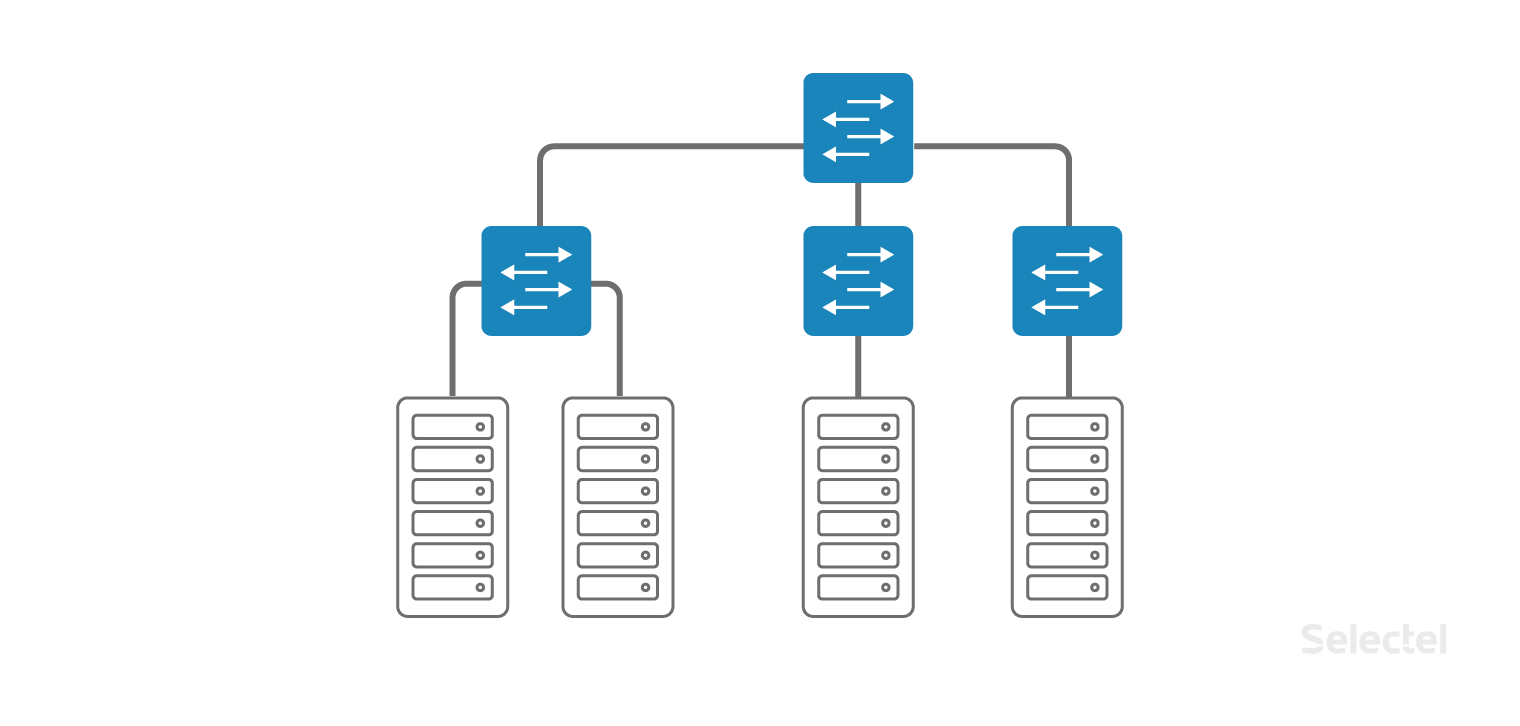
Появляются новые серверы, в том числе резервные серверы БД, серверы резервного копирования и тому подобные. Пока проект живет в одном дата-центре, проблем масштабирования, как правило, не возникает. Разработчики приложения просто привыкают, что на очередном сервере в локальной сети IP-адрес меняется только в последнем октете, а прописывать какие-то отдельные правила маршрутизации не требуется.
Аналогичную схему разработчики просят применять и при росте проекта, когда следующие серверы арендуются уже в другом дата-центре или когда какая-то часть проекта переезжает на виртуальные машины в облако. На картинке все выглядит очень просто и красиво:
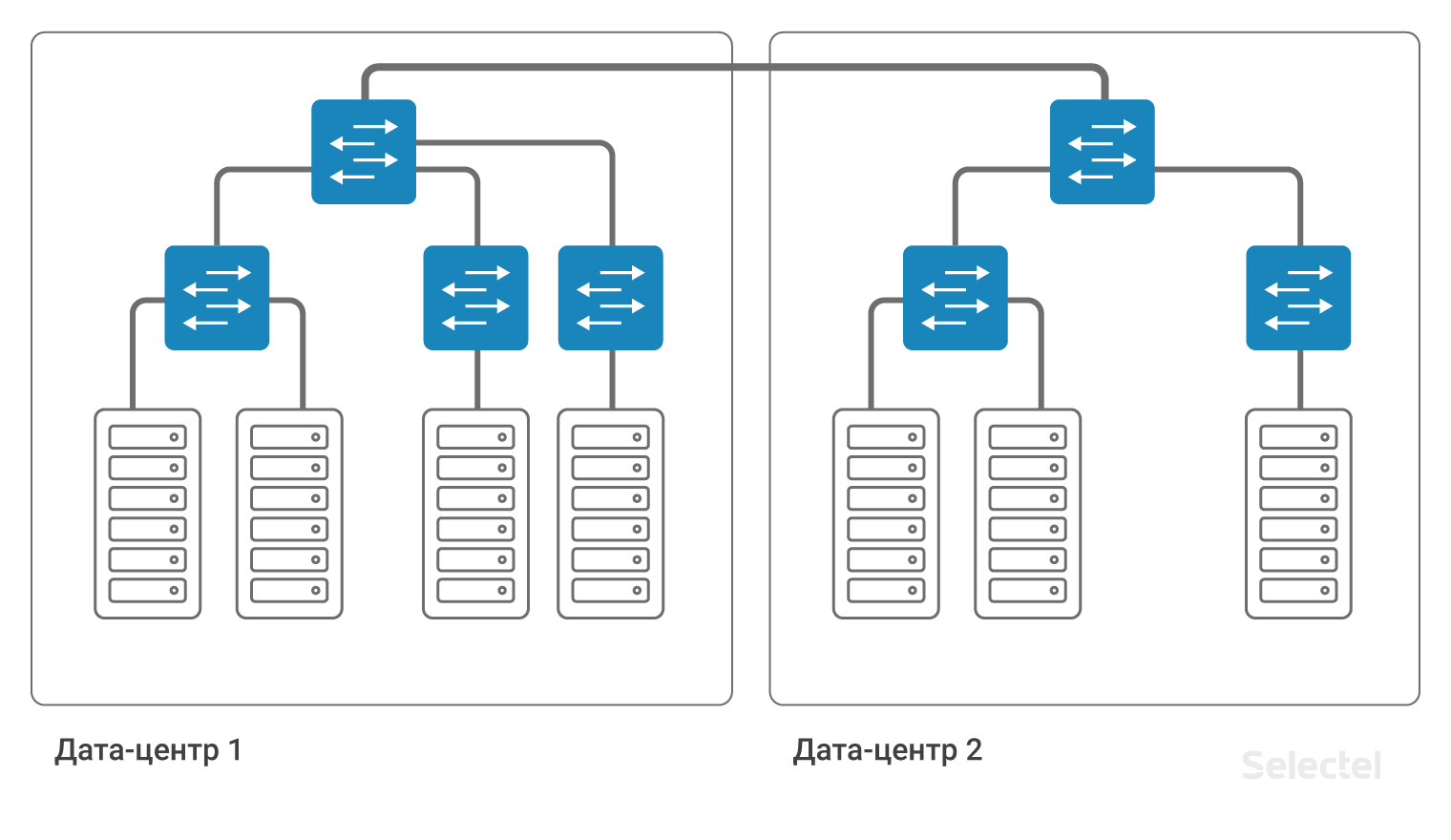
Казалось бы, надо всего лишь соединить одним VLAN два коммутатора агрегации в ДЦ1 и ДЦ2. Но что стоит за этим простым действием?
Резервирование ресурсов
Во-первых, мы увеличиваем ширину L2 домена, таким образом все потенциальные проблемы локальной сети ДЦ1 могут возникнуть в ДЦ2. Кому понравится, что его серверы расположены в ДЦ2, а инцидент, связанный с недоступностью локальной сети, произойдет по причине некорректных действий внутри ДЦ1?
Во-вторых, надо позаботиться о резервировании этого VLAN. Коммутатор агрегации в каждом дата-центре — точка отказа. Кабель между дата-центрами — еще одна точка отказа. Каждую точку отказа следует зарезервировать. Два коммутатора агрегации, два кабеля от коммутаторов агрегации до коммутаторов доступа, два кабеля между дата-центрами… Каждый раз увеличивается количество компонентов, а схема усложняется.
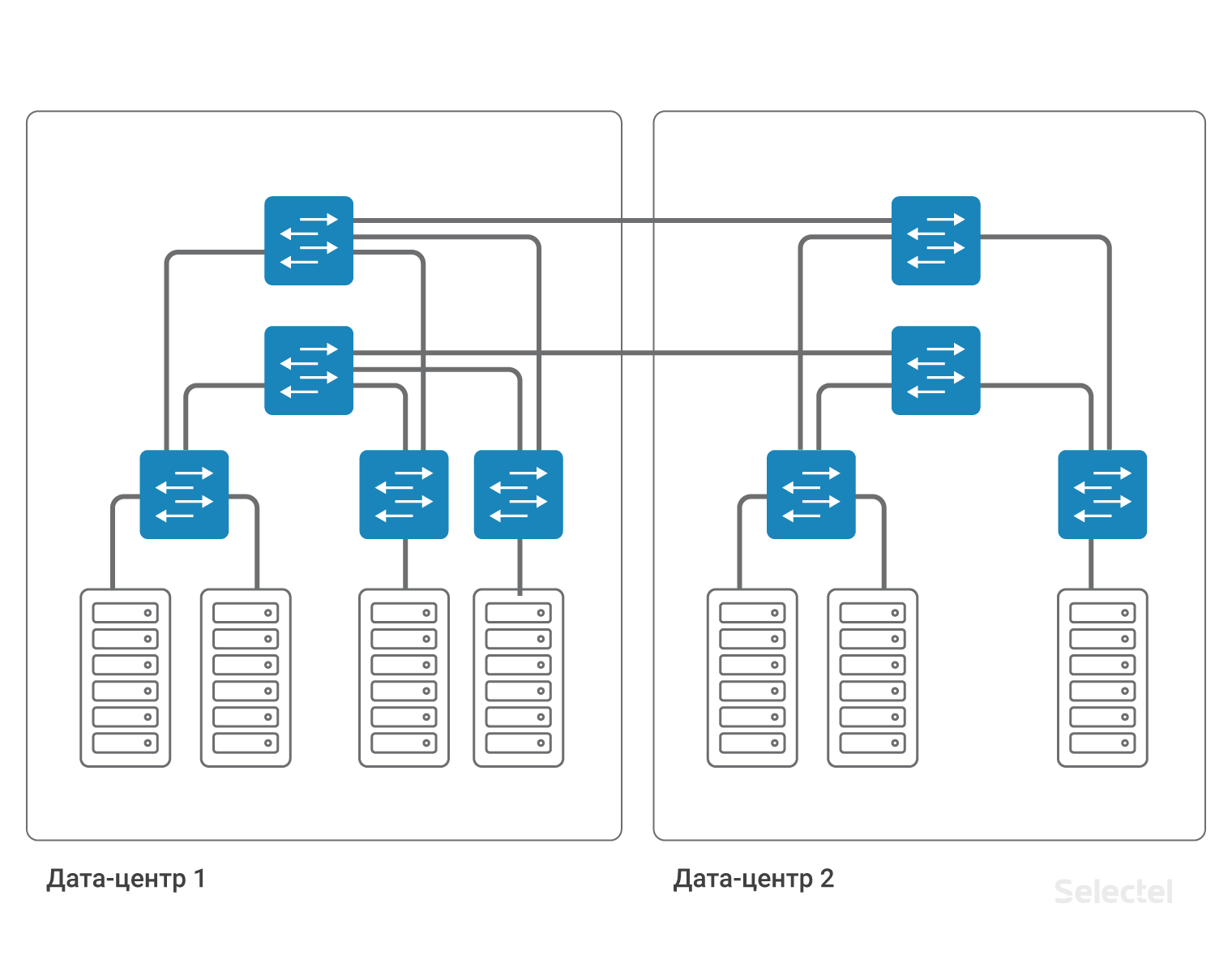
Усложнение схемы вызвано необходимостью резервирования каждого элемента в системе. Для полноценного резервирования устройств и линков требуется продублировать почти каждый элемент. На такой большой сети уже невозможно использовать STP для организации резервирования. Можно было бы все элементы сети, в частности, коммутаторы доступа, представить как составляющие MPLS-облака, тогда бы резервирование получилось за счет функционала протокола MPLS.
Но MPLS-устройства, как правило, в два раза дороже, чем не-MPLS. И надо отметить то, что MPLS-коммутатор в 1U, обладающий хорошей степенью масштабируемости, реализацией полноценного функционала MPLS в Control-plane, на практике, не существовал до последнего времени. В итоге хочется избавиться или минимизировать влияние проблем L2 на существующую сеть, но при этом сохранить возможность резервирования ресурсов.
Переход на L3
Если каждый линк в сети представить как отдельный IP-сегмент, а каждое устройство — как отдельный маршрутизатор, то нам не требуется резервирование на уровне L2. Резервирование линков и маршрутизаторов обеспечивается за счет протоколов динамической маршрутизации и избыточности маршрутизации в сети.
Внутри дата-центра мы можем сохранить существующие схемы взаимодействия серверов друг с другом по L2, а выход к серверам в другом дата-центре будет осуществляться по L3.

Таким образом, дата-центры связаны между собой L3-связностью. То есть эмулируется, что между дата-центрами установлен маршрутизатор (на самом деле, несколько, для резервирования). Это позволяет разделить L2-домены между дата-центрами, использовать в каждом дата-центре свое собственное пространство VLAN, осуществлять между ними связь. Для каждого из клиентов можно использовать повторяющиеся диапазоны IP-адресов, сети полностью изолированы друг от друга, и из сети одного клиента не попасть в сеть другого клиента (кроме случаев, когда оба клиенты согласны на такое соединение).
Мы рекомендуем использовать для локальных сетей IP-сегменты из адресации 10.0.0.0/8. Для первого дата-центра сеть будет, например, 10.0.1.0/24, для второго — 10.0.2.0/24. Selectel на маршрутизаторе прописывает IP-адрес из этой подсети. Как правило, адреса .250-.254 резервируются для сетевых устройств Selectel, а адрес .254 служит шлюзом для попадания в другие локальные сети. На все устройства во всех дата-центрах прописывается маршрут:
route add 10.0.0.0 mask 255.0.0.0 gw 10.0.x.254
Где x — номер дата-центра. За счет этого маршрута серверы в дата-центрах «видят» друг друга по маршрутизации.
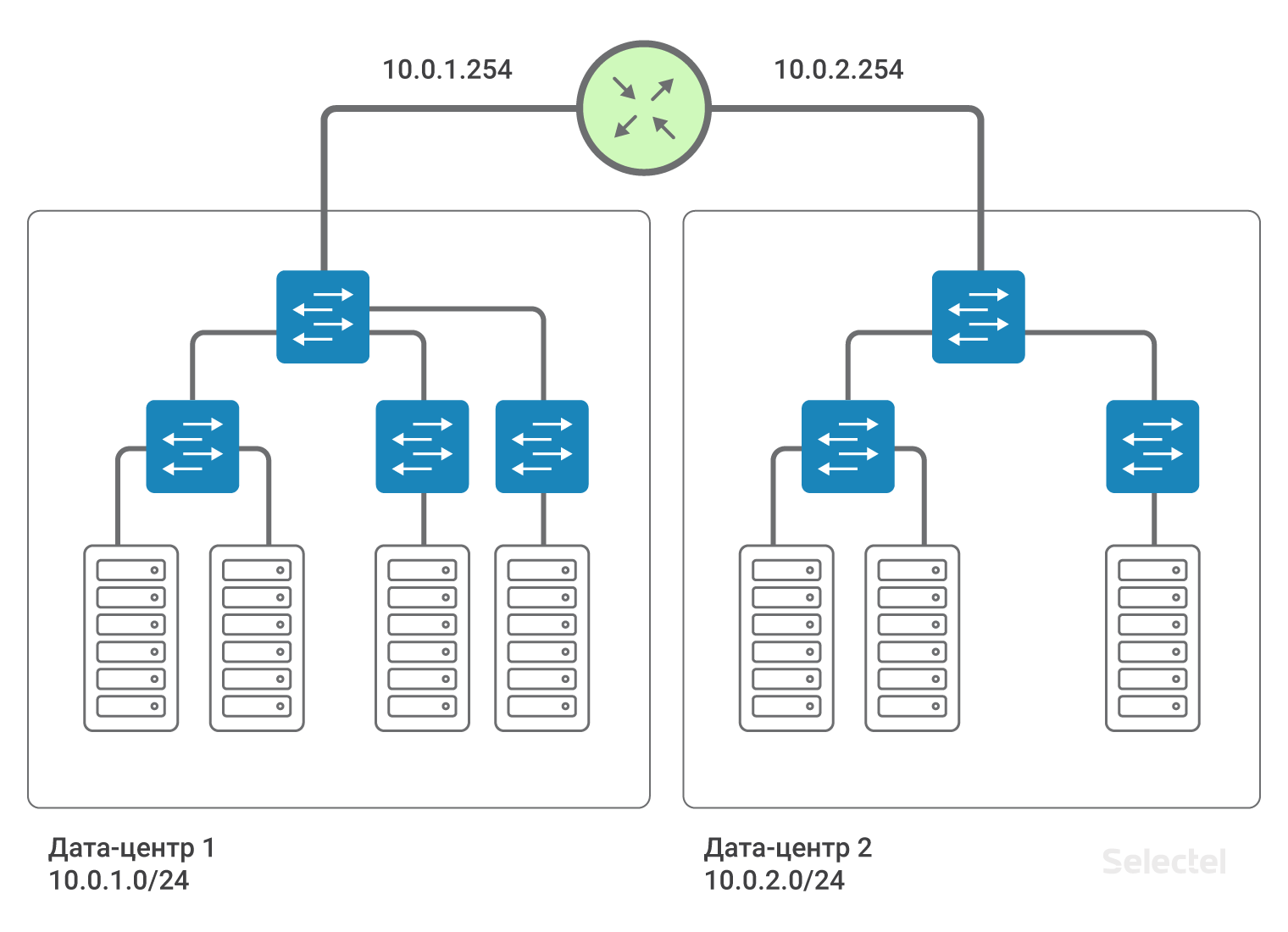
Наличие такого маршрута упрощает масштабирование схемы в случае, например, появления третьего дата-центра. Тогда для серверов в третьем дата-центре прописываются IP-адреса из следующего диапазона, 10.0.3.0/24, на маршрутизаторе — адрес 10.0.3.254.
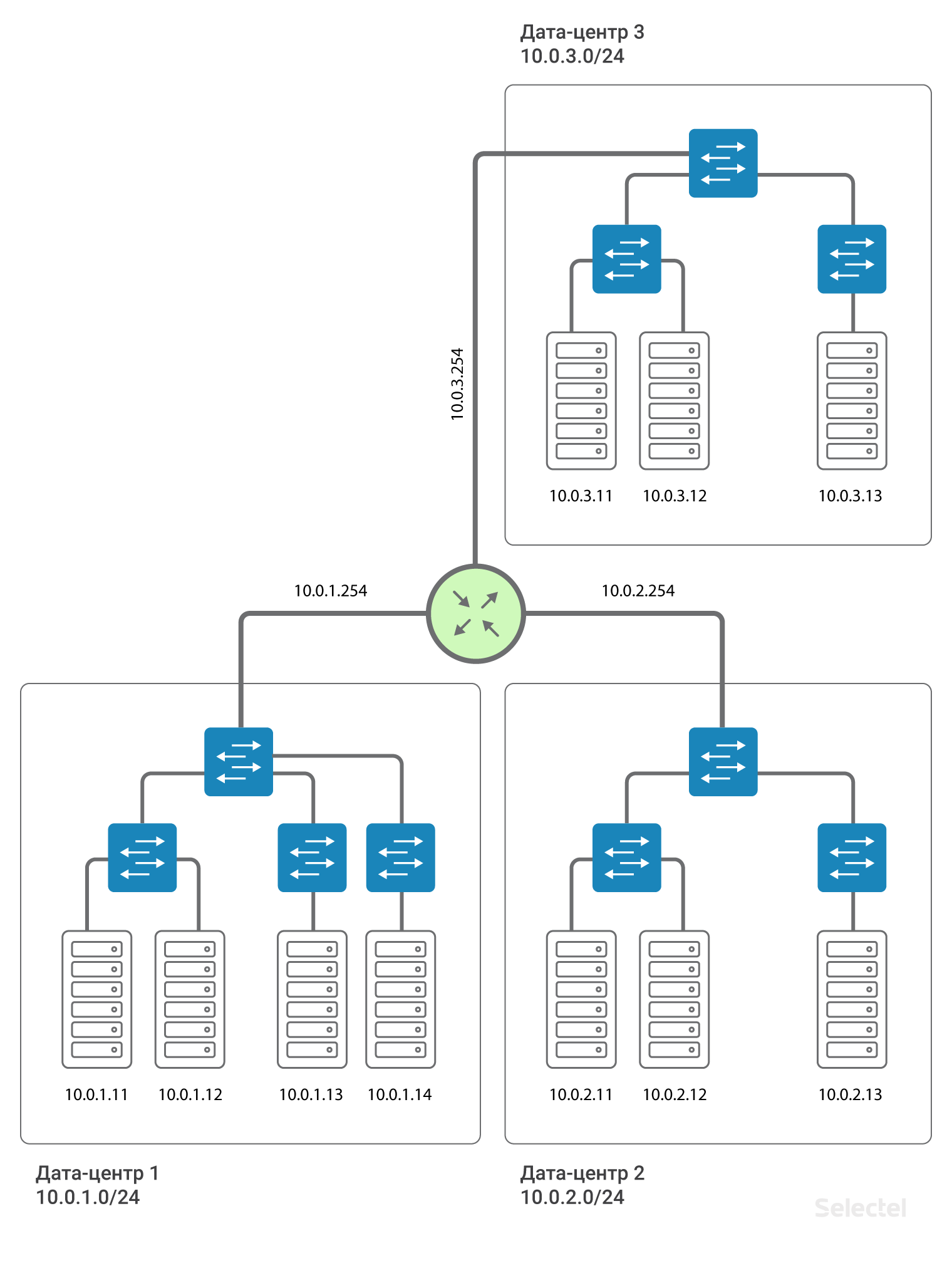
Отличительной особенностью реализации такой схемы является то, что она не требует дополнительного резервирования на случай отказа дата-центра или внешних каналов связи. Так, например, при отказе дата-центра 1 целиком сохраняется связь между дата-центром 2 и дата-центром 3, а при реализации схемы с подачей L2 между дата-центрами через какой-то один из них, как на рисунке:

От работоспособности дата-центра 1 зависит связь дата-центра 2 и дата-центра 3. Или требуется организация дополнительных линков и использование сложных схем L2 резервирования. И при сохранении L2 схемы все равно вся сеть целиком очень чувствительна к некорректной коммутации, образованию петель коммутации, различным штормам трафика и иным неприятностям.
L3-сегменты внутри проектов
Помимо использования различных L3-сегментов в разных дата-центрах, имеет смысл выделять отдельную L3 сеть для серверов в разных проектах, зачастую сделанных по разным технологиям. Например, аппаратные серверы в дата-центре в одной IP-подсети, виртуальные серверы в этом же дата-центре, но в облаке VMware, — в другой IP-подсети, какие-то серверы, относящиеся к staging, — в третьей IP-подсети. Тогда случайные ошибки в одном из сегментов не приводят к полному отказу всех серверов, входящих в локальную сеть.
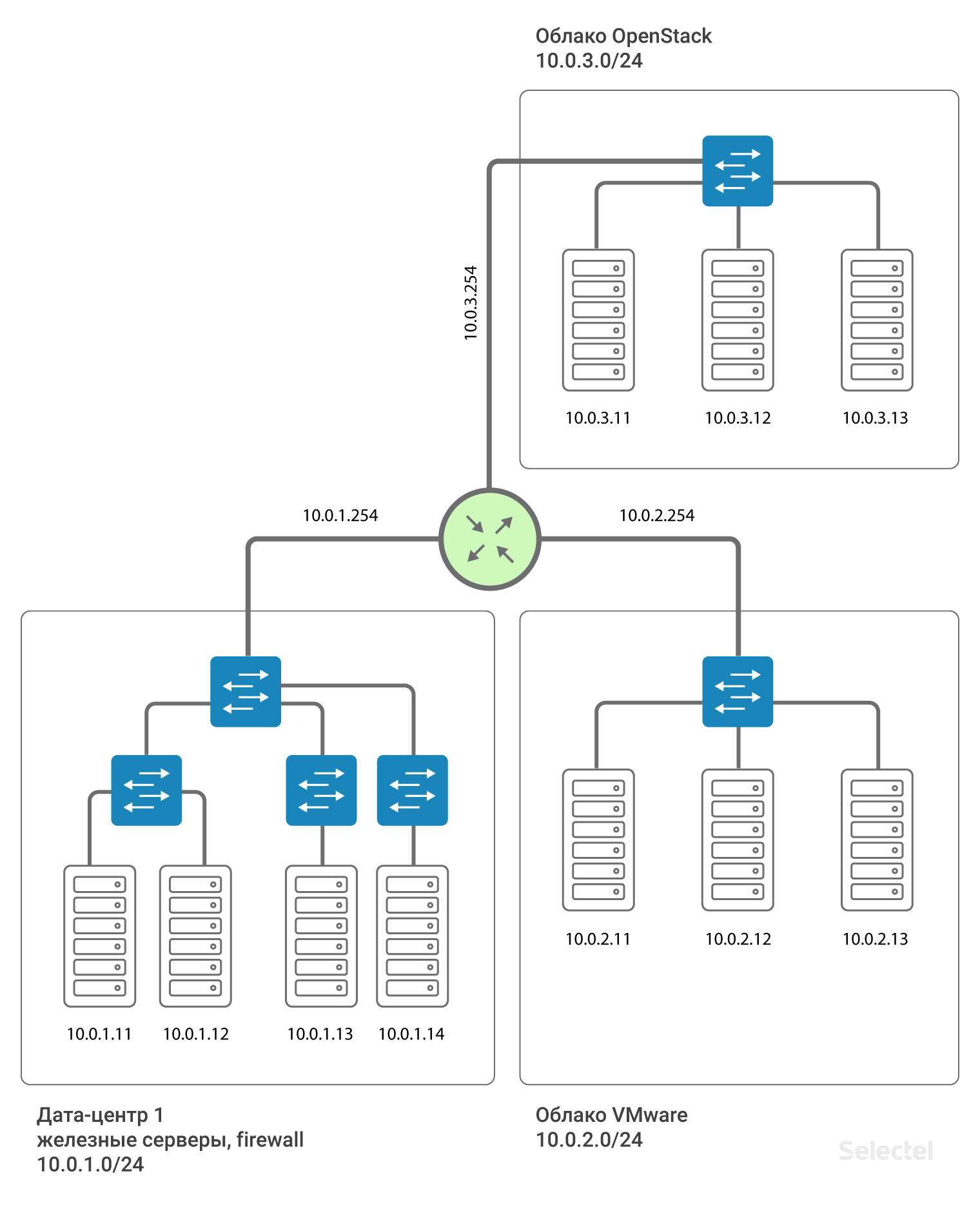
Резервирование маршрутизатора
Это все впечатляюще, но между проектами получается единая точка отказа — это маршрутизатор. Как быть в этом случае? На самом же деле, маршрутизатор не один. На каждый дата-центр выделяется два маршрутизатора, а для каждого заказчика они формируют Virtual IP .254 с использованием протокола VRRP.
Использование VRRP между двумя рядом стоящими устройствами, имеющими общий L2 сегмент, оправдано. Для дата-центров, разнесенных территориально, используются разные маршрутизаторы, а между ними организуется MPLS. Таким образом, каждый клиент, подключающийся к локальной сети по такой схеме, подключается в отдельный L3VPN, сделанный для него на этих MPLS-маршрутизаторах. И схема, в приближении к реальности, выглядит так:
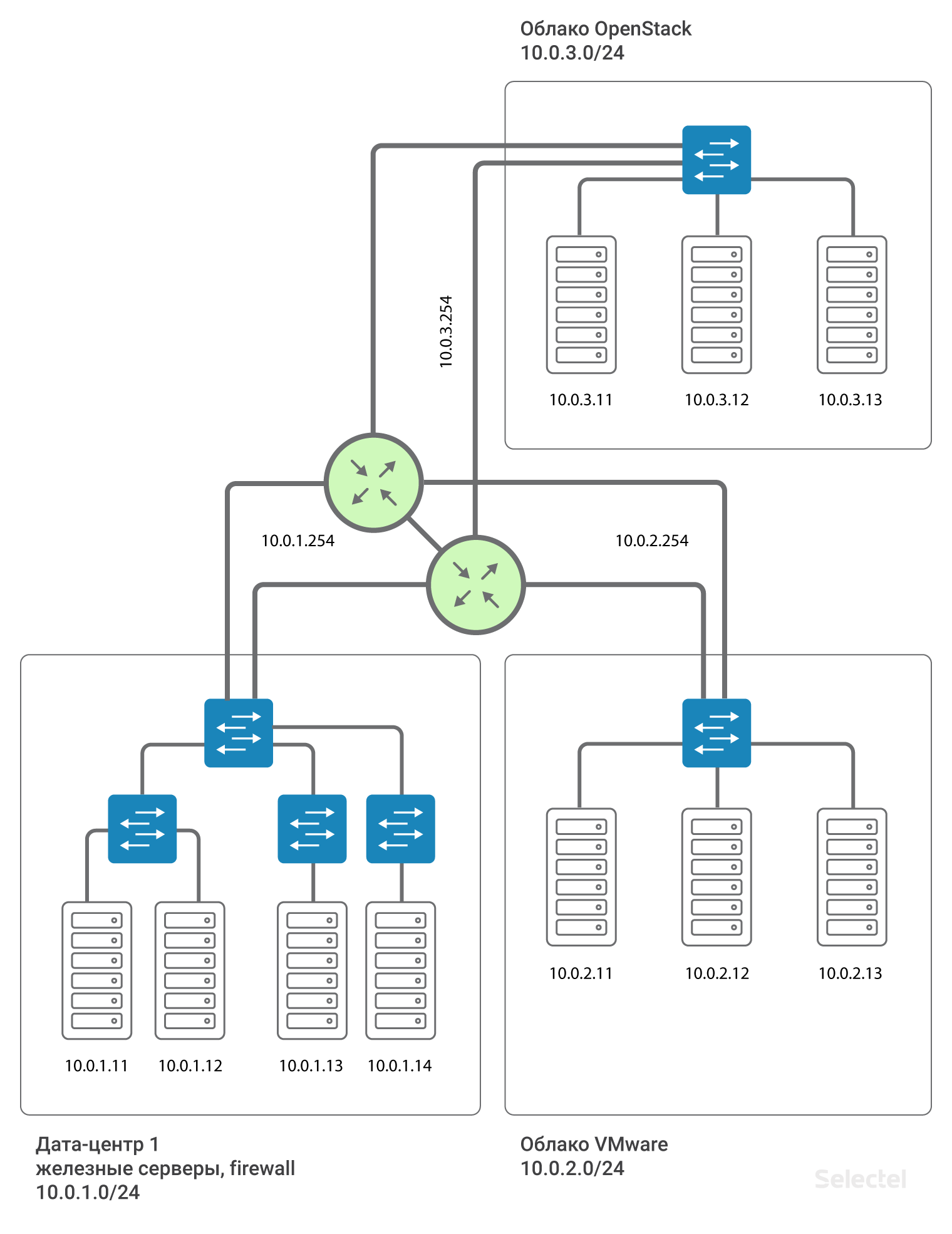
Адрес шлюза для каждого сегмента .254 резервируется по VRRP между двумя маршрутизаторами.
Заключение
Обобщая все вышесказанное — изменение типа локальной сети с уровня L2 на уровень L3 позволило нам сохранить возможность масштабирования, увеличило уровень надежности и отказоустойчивости, а также позволило реализовать схемы дополнительного резервирования. Более того это позволило обойти существующие ограничения и «подводные камни» L2.
По мере роста проектов и дата-центров существующие типовые решения достигают своего предела масштабируемости. Это означает, что для эффективного решения задач они уже не подходят. Требования к надежности и устойчивости системы в целом постоянно повышаются, что в свою очередь влияет на процесс планирования. Важно учитывать тот факт, что следует рассматривать оптимистичные прогнозы роста, чтобы в дальнейшем не получить систему, которую будет невозможно масштабировать.
Расскажите нам — применяете ли вы уже L3VPN? Ждем вас в комментариях.





