

Представьте ситуацию: ваше приложение в Kubernetes работает стабильно, но внезапно начинается пиковая нагрузка. Поды пытаются масштабироваться, HPA увеличивает их количество, но… они висят в статусе Pending. Почему? Потому что в кластере недостаточно ресурсов на нодах. Cluster Autoscaler должен добавить новые ноды, но процесс занимает много времени, иногда нода не создается из-за проблем с облаком. За это время пользователи уже получают ошибки 503, а вы теряете деньги.
Знакомо?
А теперь обратная ситуация: нагрузка спала, поды удалились, но ноды продолжают работать вхолостую. Вы платите за простаивающие ресурсы, потому что Cluster Autoscaler слишком консервативен в удалении нод или не может оптимально «упаковать» workloads.
Есть ли способ сделать это быстрее, умнее и экономичнее? Меня зовут Даниил Кондрашов, я разработчик Managed Kubernetes в Selectel. В этой статье познакомлю вас с Karpenter — современным решением для автоматического управления нодами в Kubernetes, которое решает эти проблемы принципиально иначе. Подробности в статье!
Основы автоскейлинга в Kubernetes
Прежде чем погружаться в Karpenter, важно понять общую картину автоскейлинга в Kubernetes. Масштабирование происходит на трех уровнях, и каждый решает свою задачу.
Уровень 1. Horizontal Pod Autoscaler (HPA) отвечает за горизонтальное масштабирование — увеличение или уменьшение количества подов в Deployment или StatefulSet. HPA мониторит метрики (CPU, память, кастомные метрики) и добавляет реплики, когда нагрузка растет. Это первая линия обороны против перегрузки.
Уровень 2. Vertical Pod Autoscaler (VPA) работает на уровне вертикального масштабирования — он изменяет количество ресурсов (CPU, память) внутри самого пода. VPA анализирует реальное потребление и корректирует resource requests и limits. Это полезно для приложений, которые нельзя горизонтально масштабировать, или для оптимизации ресурсов долгоживущих подов.

Уровень 3. Cluster Autoscaler (CA) — это инфраструктурный уровень. Когда HPA добавляет поды, но им не хватает места на существующих нодах, в игру вступает Cluster Autoscaler. Он добавляет новые ноды в кластер через взаимодействие с облачным провайдером. И наоборот — удаляет недоиспользуемые ноды для экономии средств.
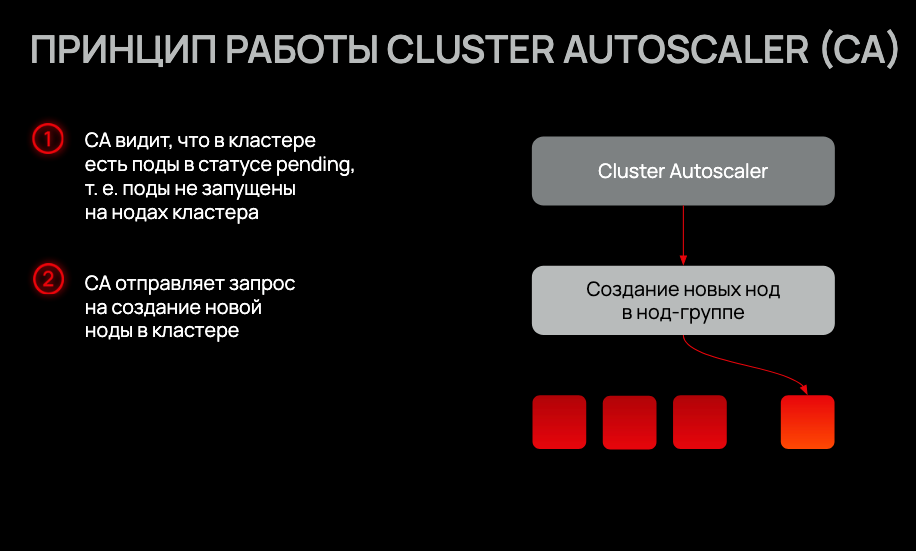
Cluster Autoscaler: возможности и ограничения
Cluster Autoscaler (CA) — это стандартное решение для автоматического управления нодами в Kubernetes. Он работает по довольно простому принципу: периодически проверяет, есть ли в кластере поды в состоянии Pending из-за нехватки ресурсов. Если да — запрашивает у облачного провайдера новые виртуальные машины из заранее настроенных Node Groups.
Основные возможности CA
- Автоматическое добавление нод при нехватке ресурсов
- Удаление недоиспользуемых нод
- Поддержка разных облачных провайдеров
Звучит неплохо, но в реальной практике начинают проявляться ограничения.
1. Жесткая привязка к Node Groups. Вам нужно заранее создать Node Groups с разными типами инстансов: CPU-оптимизированные, memory-оптимизированные и т. д. CA может выбирать только из этих предопределенных групп. Если вашему workload нужна специфическая конфигурация — придется создавать новую Node Group и переконфигурировать CA.
2. Проблемы с bin packing. CA не всегда оптимально «упаковывает» поды на ноды. Он может оставлять полупустые ноды, которые нельзя удалить, потому что на них висит один маленький под. Это приводит к переплате за ресурсы.
3. Ограниченная гибкость выбора инстансов. Даже если вы настроили несколько типов инстансов в Node Group, CA может не выбрать оптимальный. Например, под запрашивает 2 CPU и 4 ГБ памяти, а CA создает инстанс с 4 CPU и 8 ГБ, потому что так настроена Node Group.
Представьте ситуацию: у вас микросервисная архитектура, где одни сервисы требуют много CPU (обработка данных), другие — много памяти (кэширование), третьи — GPU (ML-inference). С Cluster Autoscaler вам придется создать отдельные Node Groups для каждого типа нагрузки, настроить taints и tolerations, node affinity… Конфигурация превращается в лабиринт YAML-файлов.
Знакомство с Karpenter
Karpenter — это open-source проект автоматического управления нодами, изначально разработанный командой AWS, но работающий с различными облачными провайдерами, включая Selectel, Azure, GCP, и другие. Философия Karpenter принципиально отличается от Cluster Autoscaler: вместо работы через предопределенные Node Groups, Karpenter использует подход just-in-time provisioning — создание нод точно под требования конкретных workloads в момент, когда они нужны.
Как это работает? Когда в кластере появляется Pending под, Karpenter мгновенно анализирует его требования (CPU, память, GPU, taints, affinity, topology spread constraints) и напрямую обращается к API облачного провайдера, чтобы создать виртуальную машину с оптимальной конфигурацией. Никаких предопределенных групп, никаких промежуточных абстракций — только прямое взаимодействие с облаком.
Ключевые преимущества Karpenter над Cluster Autoscaler
- Скорость реакции. Karpenter реагирует на события практически мгновенно.
- Динамический выбор типов инстансов. Karpenter может выбирать из всего каталога типов виртуальных машин провайдера. Вы задаете ограничения, например «только инстансы с не менее чем 2 CPU» или «из линейки Memory», а Karpenter сам подбирает оптимальный вариант. В Selectel это может быть выбор между Standard, CPU, Memory, Shared, GPU и High-Freq линейками в зависимости от требований.
- Лучшая оптимизация затрат. Karpenter активно использует алгоритмы bin packing для максимально плотной упаковки подов на минимальное количество нод. Более того, у него есть встроенный механизм consolidation (консолидации) — он постоянно анализирует, можно ли перераспределить workloads и использовать более экономичные по стоимости ноды, и делает это автоматически.
- Automatic deprovisioning. Karpenter не только добавляет ноды, но и умно их удаляет. Он отслеживает недоиспользуемые ноды, пустые ноды, expired ноды (по TTL) и gracefully удаляет их, предварительно перемещая workloads.
- Простота конфигурации. Вместо множества Node Groups и сложных настроек вы описываете требования в одном или нескольких ресурсах NodePool. Конфигурация более декларативная и понятная.
- Поддержка spot/preemptible instances. Karpenter может легко миксовать on-demand и spot инстансы для оптимизации затрат, автоматически заменяя прерванные spot-ноды.
Как работает Karpenter: архитектура
Чтобы эффективно использовать Karpenter, полезно понимать его внутреннее устройство. Архитектура достаточно элегантна и состоит из нескольких ключевых компонентов.
Karpenter Controller — это основной мозг системы, работающий как обычный Deployment в вашем кластере. Он выполняет несколько задач одновременно:
- отслеживает поды в состоянии Pending через Kubernetes API;
- анализирует требования этих подов (resource requests, node selectors, affinity, taints);
- принимает решения о создании новых нод;
- управляет жизненным циклом существующих нод;
- выполняет consolidation и deprovisioning.
Cloud Provider — модуль, который знает, как работать с API конкретного облачного провайдера. Для Selectel это означает знание о доступных типах виртуальных машин (Standard, CPU, Memory, High-Freq, Shared, GPU), регионах (ru-1, ru-2, и т. д).
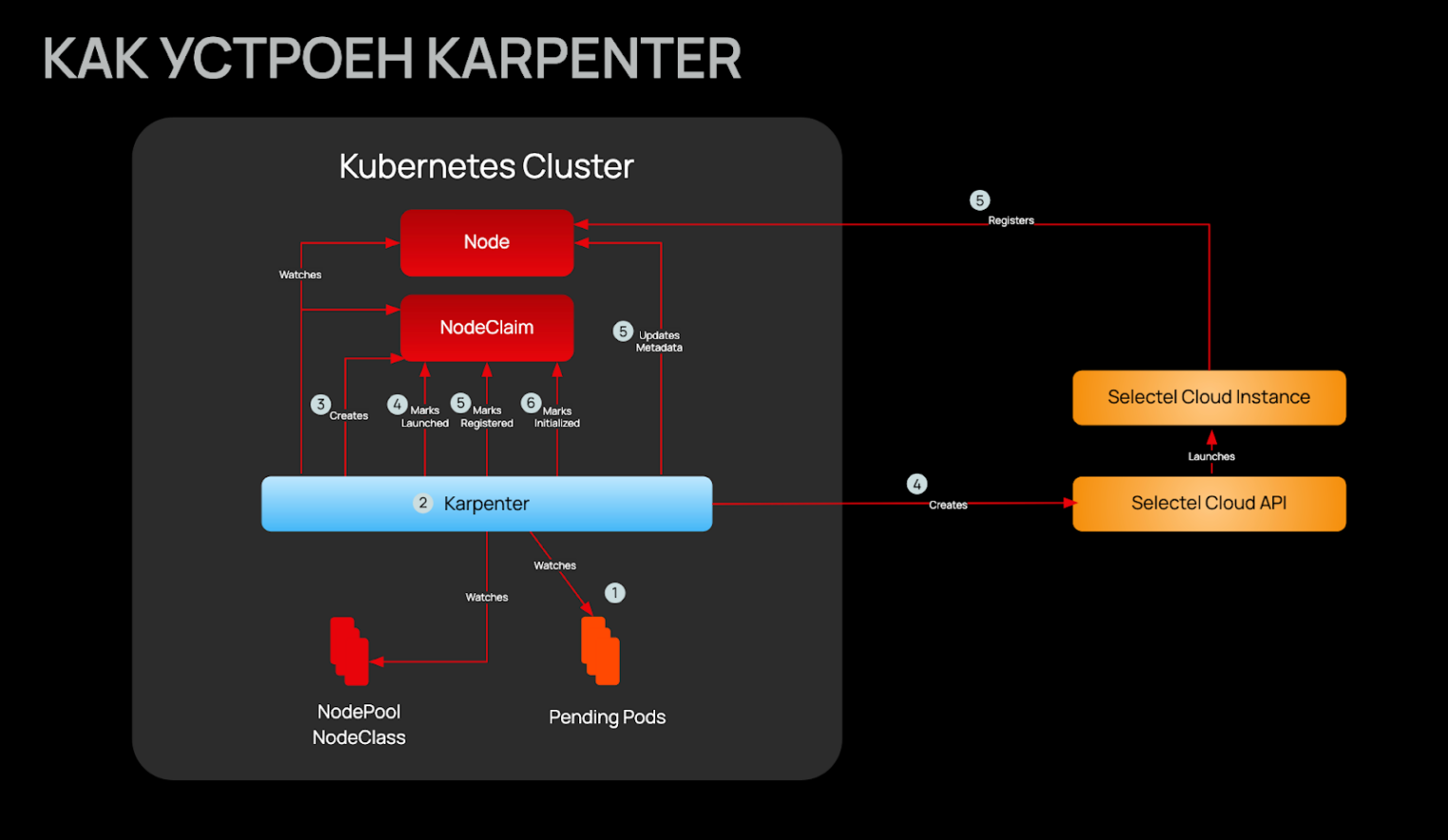
Давайте пройдемся по типичному сценарию работы.
Шаг 1. Обнаружение Pending-подов. Вы делаете kubectl scale deployment myapp –replicas=10, HPA срабатывает, или просто появляется новый workload. Kubernetes Scheduler пытается разместить поды на существующих нодах, но свободных ресурсов нет — поды переходят в состояние Pending.
Шаг 2. Анализ требований. Karpenter через мгновенно получает уведомление о Pending-подах. Он анализирует их спецификации:
– Resource requests: cpu: 1000m, memory: 2Gi,
– Tolerations для определенных taints,
– Affinity и anti-affinity правила,
– Topology spread constraints.
Шаг 3. Выбор оптимального типа инстанса. На основе собранных требований Karpenter обращается к Cloud Provider модулю: «Мне нужен инстанс, минимум 1 vCPU и 2GB RAM, желательно с хорошим соотношением цена/производительность». Модуль возвращает список подходящих типов виртуальных машин из облака, отсортированный по критериям: стоимости, производительности и доступности.
Шаг 4. Создание ноды через API. Karpenter делает прямой вызов к API Selectel для создания виртуальной машины выбранного типа. Она создается со всеми необходимыми параметрами.
Шаг 5. Регистрация в кластере. Созданная виртуальная машина запускается, устанавливаются необходимые компоненты Kubernetes (kubelet, containerd) и регистрируется в кластере как новая нода. Scheduler сразу же размещает Pending-поды на эту свежую ноду.
Параллельный процесс: Consolidation. Одновременно с мониторингом Pending-подов, Karpenter постоянно анализирует существующие ноды. Он спрашивает себя: «Могу ли я перераспределить workloads так, чтобы использовать меньше нод и меньше платить?» Если да — делает gracefully evict подов с одной ноды, переносит их на другие и удаляет освободившуюся ноду. Это происходит без простоев благодаря соблюдению PodDisruptionBudgets.
Deprovisioning (удаление нод) происходит в нескольких случаях.
- Empty nodes — еси нода пустая дольше заданного времени.
- Expired nodes — если достигнут TTL ноды (полезно для ротации нод со spot инстансами).
- Consolidation — если workloads можно упаковать плотнее.
- Drift — если конфигурация NodePool изменилась и нода больше не соответствует требованиям.
NodePool определяет требования к нодам (лимиты, instance types), а NodeClass — специфичные для облачного провайдера настройки (AMI, типы инстансов, сетевые настройки, дисков).
Базовая установка Karpenter в Selectel
Теперь перейдем к практике и установим Karpenter в кластер Managed Kubernetes. Хорошая новость: в Selectel процесс установки значительно упрощен благодаря готовому Helm chart, который уже интегрирован с облачной инфраструктурой.
Предварительные требования
Минимальная конфигурация кластера
- Kubernetes версии 1.28.
- Минимум одна нода с не менее 2 vCPU и 4 ГБ RAM для работы самого Karpenter.
Рекомендации для продакшена
- Нужны две ноды с 2 vCPU и 4 ГБ RAM — для отказоустойчивости компонентов Karpenter.
- Выключите Cluster Autoscaler в панели управления, если он активен. Karpenter и CA конфликтуют при одновременной работе.
- Отключите автовосстановление нод для групп, которыми будет управлять Karpenter.
Инструменты
- Kubectl, настроенный для работы с вашим кластером.
- Helm 3.16+, установленный локально. Для версии 3.17+ синтаксис немного отличается.
- Kubeconfig-файл для доступа к кластеру.
Получение необходимой информации
Шаг 1. Найдите ID кластера в панели управления Selectel. Для этого перейдите в Верхнее меню → Продукты → Managed Kubernetes, выберите ваш кластер и скопируйте Cluster ID — он находится под именем кластера, рядом с регионом и пулом.
Шаг 2. Подготовьте kubeconfig. Если вы еще не скачали kubeconfig-файл, перейдите в панель управления на странице кластера и нажмите Скачать kubeconfig. Сохраните файл, например, как my-cluster.yaml.
Установка Karpenter
Шаг 1. Экспортируйте путь к kubeconfig и проверьте доступ к кластеру:
kubectl apply -f nodeclass.yaml
# Проверяем создание:
kubectl get selectelnodeclass
# Вывод:
# NAME AGE
# default 5s
Шаг 2.1. Установите Karpenter через Helm.
Для Helm 3.17 и выше:
kubectl apply -f nodeclass.yaml
# Проверяем создание:
kubectl get selectelnodeclass
# Вывод:
# NAME AGE
# default 5s
Для Helm 3.16 и ниже:
kubectl apply -f nodeclass.yaml
# Проверяем создание:
kubectl get selectelnodeclass
# Вывод:
# NAME AGE
# default 5s
Шаг 2.2. Замените <your-cluster-id> на ID вашего кластера, который вы скопировали на предыдущем шаге. Пример:
kubectl apply -f nodeclass.yaml
# Проверяем создание:
kubectl get selectelnodeclass
# Вывод:
# NAME AGE
# default 5s
При установке Helm скачивает chart из GitHub, создаются Deployment и Service для Karpenter controller, устанавливаются необходимые RBAC права. На последнем этапе Karpenter автоматически получает credentials для работы с Selectel API через интеграцию с Managed Kubernetes.
Шаг 3. Проверьте установку. Дождитесь, пока под Karpenter запустится и проверьте логи для подтверждения успешной инициализации:
kubectl apply -f nodeclass.yaml
# Проверяем создание:
kubectl get selectelnodeclass
# Вывод:
# NAME AGE
# default 5s
kubectl apply -f nodeclass.yaml
# Проверяем создание:
kubectl get selectelnodeclass
# Вывод:
# NAME AGE
# default 5s
Если в логах есть ошибки аутентификации или подключения к API, проверьте правильность указания Cluster ID.
На этом базовая установка завершена! Karpenter запущен, но пока не будет создавать ноды, так как мы ещё не настроили NodePool и NodeClass. Перейдем к настройке в следующем разделе.
Настройка Karpenter для Selectel
После установки необходимо настроить два ключевых ресурса: NodeClass, который определяет инфраструктурные параметры нод, и NodePool, который описывает правила подбора и масштабирования. Давайте разберемся, как это работает в Selectel.
Создание SelectelNodeClass
SelectelNodeClass — это Selectel-специфический ресурс, который определяет параметры дисков для создаваемых нод. В отличие от общего Karpenter, где нужно настраивать AMI, security groups и другие низкоуровневые детали, в Selectel все проще — достаточно указать тип и размер загрузочного сетевого диска.
Начнем с базовой конфигурации для сетевых дисков:
kubectl apply -f nodeclass.yaml
# Проверяем создание:
kubectl get selectelnodeclass
# Вывод:
# NAME AGE
# default 5s
Применяем конфигурацию:
kubectl apply -f nodeclass.yaml
# Проверяем создание:
kubectl get selectelnodeclass
# Вывод:
# NAME AGE
# default 5s
Создание NodePool
Теперь создадим NodePool — ресурс, который описывает, какие ноды может создавать Karpenter и когда. NodePool использует мощную систему requirements (требований) для фильтрации доступных конфигураций из облака Selectel.
Базовый NodePool:
# nodepool-basic.yaml
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: default
spec:
template:
spec:
# Ссылка на SelectelNodeClass, который мы создали ранее
nodeClassRef:
name: default
kind: SelectelNodeClass
group: karpenter.k8s.selectel
# Requirements — фильтры для выбора конфигураций
requirements:
# Сегменты (availability zones) Selectel
- key: topology.kubernetes.io/zone
operator: In
values: ["ru-7a", "ru-7b"] # Регион ru-7 с зонами a и b
# Конкретные флейворы (конфигурации) из каталога Selectel
- key: node.kubernetes.io/instance-type
operator: In
values:
- "SL1.1-2048" # 1 vCPU, 2GB RAM (SL1 линейка, 1 поколение)
- "SL1.2-4096" # 2 vCPU, 4GB RAM
- "SL1.2-8192" # 2 vCPU, 8GB RAM
# Тип нод: on-demand (классические) или spot (прерываемые)
- key: karpenter.sh/capacity-type
operator: In
values: ["on-demand"]
# Настройки жизненного цикла нод
disruption:
# WhenEmptyOrUnderutilized — удалять или заменять ноды,
# если они пустые или недоиспользуются
consolidationPolicy: WhenEmptyOrUnderutilized
# Время ожидания перед консолидацией (0s = немедленно)
consolidateAfter: 0s
# Глобальные лимиты на ресурсы этого NodePool
limits:
cpu: "1000" # Максимум 1000 vCPU суммарно
memory: 1000Gi # Максимум 1000 GiB памяти
Применяем:
kubectl apply -f nodepool-basic.yaml
# Проверяем:
kubectl get nodepool
# Вывод:
# NAME NODECLASS NODES READY AGE
# default default 0 True 7s
Важные моменты базовой конфигурации
- topology.kubernetes.io/zone — определяет зоны доступности в регионе Selectel. Для регионов Selectel это ru-7a/b, ru-2a/b, и т. д.
- node.kubernetes.io/instance-type — конкретные флейворы (конфигурации виртуальных машин). Полный список доступных флейворов можно посмотреть в документации Selectel.
- consolidationPolicy — указывает, как Karpenter управляет существующими нодами: WhenEmpty (только полностью пустые ноды, без подов, daemon set не считаются нагрузкой) и рекомендуемый WhenEmptyOrUnderutilized (пустые и недоиспользуемые).
Продвинутый Karpenter: использование расширенных фильтров
Практический пример: CPU-workload приложение
Теперь давайте создадим реальное приложение и посмотрим, как Karpenter справляется с его развертыванием. Мы создадим CPU-workload Deployment, который будет размещен на нодах из нашего cpu-workload NodePool.
# app-data-processor.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: data-processor
namespace: default
spec:
replicas: 5 # Создаем 5 реплик для демонстрации масштабирования
selector:
matchLabels:
app: data-processor
template:
metadata:
labels:
app: data-processor
spec:
# Node selector гарантирует размещение именно на нодах cpu-workload NodePool
nodeSelector:
workload-type: cpu-workload
containers:
- name: processor
# Используем stress для имитации CPU нагрузки
image: polinux/stress
command: ["stress"]
args:
- "--cpu"
- "2" # Нагружаем 2 CPU ядра
- "--timeout"
- "3600s" # Работаем 1 час
resources:
requests:
cpu: "2000m" # Запрашиваем 2 vCPU
memory: "2Gi" # И 2GB памяти
limits:
cpu: "2000m"
memory: "2Gi"
Применяем Deployment:
kubectl apply -f app-data-processor.yaml
Наблюдаем за работой Karpenter
Сразу после применения откройте несколько терминалов для наблюдения.
Терминал 1. Статус подов:
kubectl get pods -l app=data-processor -o wide --watch
Терминал 2. Статус нод:
kubectl get nodes -L workload-type --watch
Терминал 3. Логи Karpenter:
kubectl logs -n kube-system -l app.kubernetes.io/name=karpenter -f
Что происходит
Поды создаются и переходят в статус Pending, так как в кластере нет подходящих нод с label workload-type: cpu-workload.
kubectl get pods -l app=data-processor
# NAME READY STATUS RESTARTS AGE
# data-processor-7c7444754d-k2xhk 0/1 Pending 0 2s
# data-processor-7c7444754d-pclhk 0/1 Pending 0 2s
# data-processor-7c7444754d-vdcxr 0/1 Pending 0 2s
# data-processor-7c7444754d-x5dmp 0/1 Pending 0 2s
# data-processor-7c7444754d-zjz6z 0/1 Pending 0 2s
Karpenter обнаруживает Pending поды и анализирует их требования.
- Требуют 2 vCPU и 2 ГБ RAM каждый (итого: 10 vCPU, 10 ГБ RAM).
- Имеют toleration для workload-type: cpu-workload.
- Должны быть размещены на нодах с label workload-type: cpu-workload.
В логах Karpenter вы увидите:
{"level":"INFO","msg":"found provisionable pods","count":5}
{"level":"INFO","message":"computed new nodeclaim(s) to fit pod(s)","nodeclaims":1,"pods":5}
{"level":"INFO","message":"created nodeclaim","NodePool":{"name":"cpu-workload"},"NodeClaim":{"name":"cpu-workload-vkvlt"},"requests":{"cpu":"10300m","memory":"10Gi","pods":"8"},"instance-types":"SL1.12-49152, SL1.12-49152-512, SL1.16-65536, SL1.16-65536-768, SL1.24-98304 and 1 other(s)"}
Karpenter принимает решение создать одну ноду типа SL1.12-49152 (12 vCPU, 48 ГБ RAM) из линейки Standard Line. Для этого есть несколько причин.
- Требования: минимум 10 vCPU и 10 ГБ RAM.
- Фильтр instance-cpu > 4 разрешает конфигурации с 8, 16, 32+ vCPU.
- Karpenter выбирает оптимальную конфигурацию.
В логах видим:
{"level":"INFO","message":"launched nodeclaim","instance-type":"SL1.12-49152","zone":"ru-7a","capacity-type":"on-demand","allocatable":{"cpu":"11900m","memory":"46581940224","pods":"110"}}
Karpenter обращается к API Selectel для создания виртуальной машины. Как итог — она создана, запущена и регистрируется в кластере.
kubectl get nodes -L workload-type
# NAME STATUS ROLES AGE VERSION WORKLOAD-TYPE
# test-cluster-node-9p4q7 Ready <none> 131m v1.32.9
# test-cluster-node-amc7k Ready <none> 119s v1.32.9 cpu-workload
# test-cluster-node-dud6b Ready <none> 131m v1.32.9

Scheduler размещает все пять подов на новую ноду. Поды переходят из Pending в Running.
kubectl get pods -l app=data-processor -o wide
# NAME READY STATUS NODE
# data-processor-7c7444754d-k2xhk 1/1 Running test-cluster-node-amc7k
# data-processor-7c7444754d-pclhk 1/1 Running test-cluster-node-amc7k
# data-processor-7c7444754d-vdcxr 1/1 Running test-cluster-node-amc7k
# data-processor-7c7444754d-x5dmp 1/1 Running test-cluster-node-amc7k
# data-processor-7c7444754d-zjz6z 1/1 Running test-cluster-node-amc7k
Время от создания Deployment до Running подов составляет примерно 180 секунд!
Теперь давайте посмотрим, насколько эффективно Karpenter распределил ресурсы:
# Смотрим утилизацию ноды
kubectl top node test-cluster-node-amc7k
# NAME CPU(cores) CPU(%) MEMORY(bytes) MEMORY(%)
# test-cluster-node-amc7k 10048m 84% 465Mi 1%
Отлично! Нода утилизирована на 84% CPU (10 из 16 vCPU используются подами), при этом память практически не используем, так как сценарий — тестовый.
# Детальная информация о размещении подов на ноде
kubectl describe node test-cluster-node-amc7k | grep -A 10 "Allocated resources"
# Allocated resources:
# Resource Requests Limits
# -------- -------- ------
# cpu 10300m (86%) 10 (84%)
# memory 10Gi (23%) 10Gi (23%)
Демонстрация умной consolidation
Далее давайте уменьшим количество реплик и посмотрим, как Karpenter оптимизирует ресурсы:
# Уменьшаем количество реплик до 2
kubectl scale deployment data-processor --replicas=2
Что происходит
Три пода удаляются, на ноде остается только два пода. Как итог — из 12 vCPU и 48 ГБ используются всего 4 vCPU и 4 ГБ RAM соответственно.
kubectl get pods -l app=data-processor
# NAME READY STATUS RESTARTS AGE
# data-processor-7c7444754d-k2xhk 1/1 Running 0 6m15s
# data-processor-7c7444754d-pclhk 1/1 Terminating 0 6m15s
# data-processor-7c7444754d-vdcxr 1/1 Terminating 0 6m15s
# data-processor-7c7444754d-x5dmp 1/1 Terminating 0 6m15s
# data-processor-7c7444754d-zjz6z 1/1 Running 0 6m15s
Karpenter замечает, что нода сильно недоиспользуется (всего 36% CPU). Благодаря настройке consolidationPolicy: WhenEmptyOrUnderutilized и consolidateAfter: 30s, Karpenter принимает решение об оптимизации.
В логах видим:
{"level":"INFO","message":"disrupting node(s)","reason":"underutilized","decision":"replace","disrupted-node-count":1,"replacement-node-count":1,"pod-count":2,"disrupted-nodes":[{"Node":{"name":"test-cluster-node-amc7k"},"NodeClaim":{"name":"cpu-workload-vkvlt"},"capacity-type":"on-demand","instance-type":"SL1.12-49152"}],"replacement-nodes":[{"capacity-type":"on-demand","instance-types":"SL1.6-32768, SL1.8-32768, SL1.6-32768-256, SL1.8-32768-384"}]}
{"level":"INFO","message":"created nodeclaim","NodePool":{"name":"cpu-workload"},"NodeClaim":{"name":"cpu-workload-nf8ck"},"requests":{"cpu":"4300m","memory":"4Gi","pods":"5"},"instance-types":"SL1.6-32768, SL1.6-32768-256, SL1.8-32768, SL1.8-32768-384"}
Новая виртуальная машина создана, запущена и регистрируется в кластере.
kubectl get nodes -L workload-type
# NAME STATUS ROLES AGE VERSION WORKLOAD-TYPE
# test-cluster-node-9p4q7 Ready <none> 52m v1.32.9
# test-cluster-node-dud6b Ready <none> 52m v1.32.9
# test-cluster-node-mv1cs Ready <none> 7m43s v1.32.9 cpu-workload

Scheduler размещает все два пода на новую ноду. Поды переходят из Pending в Running.
kubectl get pods -l app=data-processor -o wide
# NAME READY STATUS NODE
# data-processor-7c7444754d-crzt5 1/1 Running test-cluster-node-kj1dt
# data-processor-7c7444754d-f8qzg 1/1 Running test-cluster-node-kj1dt
Давайте посмотрим, насколько эффективно Karpenter подобрал ресурсы:
# Смотрим утилизацию ноды
kubectl top node test-cluster-node-vic00
# NAME CPU(cores) CPU(%) MEMORY(bytes) MEMORY(%)
# test-cluster-node-kj1dt 4046m 68% 433Mi 1%
Хороший результат! Нода утилизирована на 68% CPU (4 из 6 vCPU используются подами). После переезда подов прошлая виртуальная машина удаляется.
Заключение
Karpenter представляет собой современный и эффективный подход к управлению динамическими нагрузками в Kubernetes. В отличие от традиционного Cluster Autoscaler, Karpenter обеспечивает оптимизацию затрат, гибкость и простоту.
- Умная упаковка workloads и automatic consolidation снижают расходы
- Есть динамический выбор типов инстансов без предопределенных Node Groups.
- Декларативная конфигурация через NodePools гарантирует простоту вместо сложных настроек.
Для команд, работающих с Managed Kubernetes Selectel, Karpenter особенно полезен при работе с микросервной архитектурой с разнородными требованиями к ресурсам, batch-обработкой с пиковыми нагрузками, Dev-/Staging-окружениями с непредсказуемой активностью и не только. Иначе говоря, решение особенно актуально для cost-sensitive проектов, в которых важна оптимизация затрат, и приложений с SLA, которые требуют быстрого масштабирования.
Но помните, Karpenter — не серебряная пуля. Он требует правильной настройки resource requests в подах, понимания динамики системы, мониторинга и alerting, а также регулярного пересмотра конфигурации.
Куда двигаться дальше
Если вы хотите глубже изучить Karpenter, обратите внимание на официальную документацию и лучшие практики. А если строите инфраструктуру на базе нашего Managed Kubernetes, рекомендуем сохранить в закладки справочник по работе с сервисом.
Рекомендация. Не поленитесь начать с тестового кластера в Selectel — разверните простой NodePool и поэкспериментируйте с масштабированием. Постепенно повышайте уровень сложность: добавляйте разные типы workloads, spot instances и consolidation.
Только после уверенного понимания системы переходите к продакшену. Автоматическое масштабирование в Kubernetes — это искусство баланса между производительностью, стоимостью и надежностью. Karpenter дает вам инструменты для достижения этого баланса. Удачи в оптимизации ваших кластеров!





