

Самый простой способ переноса данных в кластер – это копирование файлов через веб-интерфейс файлового менеджера в панели управления Hue. Веб-интерфейс расположен по адресу http://[Hue_node]:8888/filebrowser/ (вместо [Hue_node] указывается адрес узла, на котором развернут Hue). Он интуитивно понятен и не требует дополнительных пояснений.
Веб-интерфейс хорош для начинающих пользователей; с его помощью удобно исследовать структуру каталогов HDFS. В то же время он неудобен для загрузки файлов большого объема (от нескольких гигабайт).
Для загрузки большого количества файлов или файлов большого объема предпочтительнее копировать файлы в HDFS с помощью утилиты hadoop. Эта операция осуществляется при помощи следующей команды, выполняемой с любого сервера, входящего в HDFS-кластер:
hadoop fs -put file_for_hadoop /path/to/put/file/in/HDFS/
При этом всегда можно использовать традиционные пайпы или предварительно копировать файлы на сервер.
Описанные способы хорошо подходят для ситуаций, когда необходимо перенести в HDFS уже имеющиеся данные. Но более естественным представляется собирать данные сразу же в Hadoop. Для этой цели используются специализированные инструменты. Один из таких инструментов разрабатывается в рамках проекта Apache Hadoop. Речь идет о Flume – универсальном инструменте для сбора логов и других данных. В этой статье мы хотели бы рассказать об архитектуре Flume и поделиться практическим опытом его использования.
О проекте Flume
Слово flume в переводе означает «канал». Этот инструмент и предназначен для того, чтобы управлять потоками данных: собирать их из различных источников и направлять их в централизованное хранилище.
Проект Flume разрабатывается фондом Apache Software Foundation. Первые версии Flume вышли в 2009 году. Все версии, выпущенные до 2011 года (до версии 0.9.4), называют Flume OG (OG – old generation, т.е. старое поколение). В 2011 году была начата работа над новой веткой проекта, в рамках которой предполагается существенно расширить функциональность Flume OG. Эта ветка известна под названием Flume 728 (по номеру задачи в JIRA, в который были перечислены все основные замечания и предложения по доработке) или Flume NG (NG означает new generation, т.е. новое поколение). Последняя на сегодняшний день версия 1.4.0 была выпущена в июле 2013 года.
Архитектура
Основные понятия
Описание архитектуры Flume начнем с определения основных понятий:
- событие (event) — набор данных, передаваемый Flume из точки происхождения в точку назначения;
- поток (flow) — путь движения событий от точки происхождения до точки назначения;
- клиент (client) — любое приложение, передающее данные агенту Flume;
- агент (agent) — независимый процесс, в котором выполняются такие компоненты, как источники, каналы и стоки; осуществляет хранение событий и передачу на следующий узел;
- источник (source) — интерфейс, принимающий сообщения через различные протоколы передачи данных. Полученные события источник передает на один или несколько каналов. Flume поддерживает cледующие стандарты передачи данных из внешних источников: Avro, log4j, syslog, HTTP Post c телом JSON. С помощью библиотеки ExecSource можно реализовать поддержку других стандартов;
- канал (channel) — временное хранилище для событий. Событие находится в канале до тех пор, пока не будет забрано из него стоком. Каналы хранят очереди событий, что позволяет разделить стоки и источники с различной производительностью и архитектурой. В зависимости от типа канала события могут храниться в памяти, обычном файле на диске или в базе данных (например, канал JDBC);
- сток (sink) — реализация интерфейса, забирающая событие из канала и передающая следующему агенту в потоке или сохраняющая его в конечное хранилище (например, HDFS). Стоки, передающие событие в конечное хранилище, называются конечными стоками. Примерами конечных стоков могут служить файловая система HDFS, база данных Hive, поисковый сервер Solr. В качестве примера обычного стока можно привести Avro, который просто передает сообщения другим агентам.
Структура потока
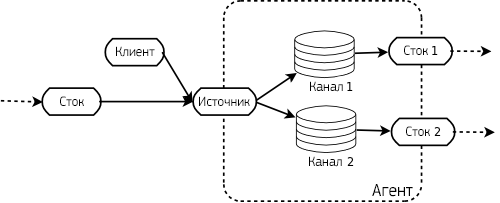
Поток начинается с клиента, который передает событие агенту (говоря более точно, на источник в составе агента). Источник, получивший событие, передает его на один или несколько каналов. Из каналов событие передается на стоки, входящие в состав того же агента. Он может передать ее другому агенту, или (если это конечный агент) — на узел назначения.
Так как источник может передавать события на несколько каналов, потоки могут направляться на несколько узлов назначения. Это наглядно показано на рисунке ниже: агент считывает событие в два канала (Канал 1 и Канал 2), и затем передает их в независимые стоки.
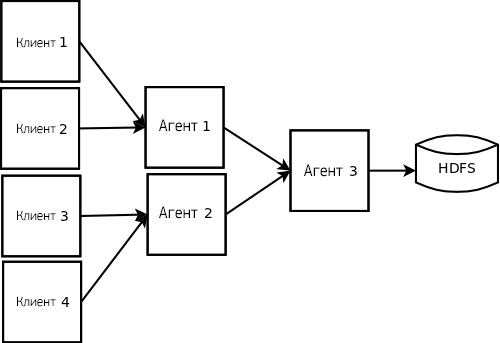
Несколько потоков можно объединить в один. Для этого нужно, чтобы несколько источников в составе одного и того же агента передавали данные на один и тот же канал. Схема взаимодействия компонентов при объединении потоков показана на рисунке ниже (здесь каждый из трех агентов, включающий несколько источников, передает данные на один и тот же канал и затем на сток):
Обеспечение надежности и обработка ошибок
Передача данных между источниками и каналами, а также между агентами, осуществляется с использованием транзакций, благодаря чему обеспечивается сохранность данных.
Обработка ошибок также осуществляется на базе транзакционного механизма. Когда поток проходит через несколько различных агентов, и при прохождении возникают проблемы связи, события буферизуются на последнем доступном в потоке агенте. Более наглядно схема обработки ошибок представлена на рисунке ниже:
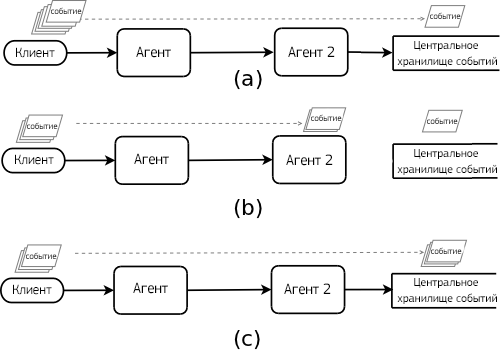
Обработка ошибок в потоке: (а) события движутся от клиента к центральному хранилищу без проблем связи; (b) возникла проблема связи на участке между Агентом2 и центральным хранилищем, и события буферизуются на Агенте2; (с) после устранения проблем связи события, буферизованные на Агенте2, были отправлены в центральное хранилище.
Установка Flume через Cloudera Manager
Так как мы уже развернули кластер Cloudera Hadoop (см. предыдущую статью), мы будем устанавливать Flume с помощью Cloudera Manager. На странице со списком сервисов кластера выберем «Actions» → «Add a Service».
Выбираем «Flume» и нажимаем на кнопку «Continue»:
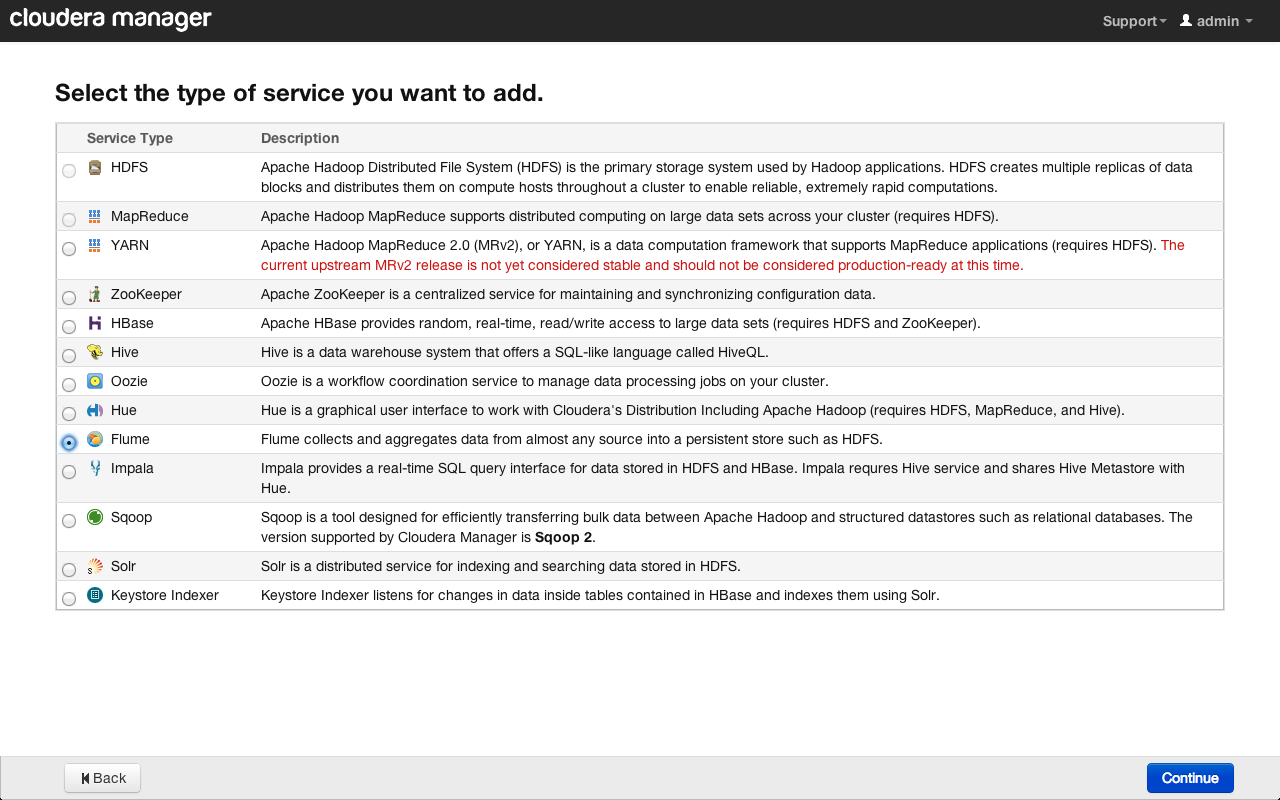
Теперь выберем Zookeeper-сервис, с которым будет связан наш сервис Flume. Можно создать несколько кластеров или однотипных сервисов, контролируемых различными Zookeeper-инстансами.
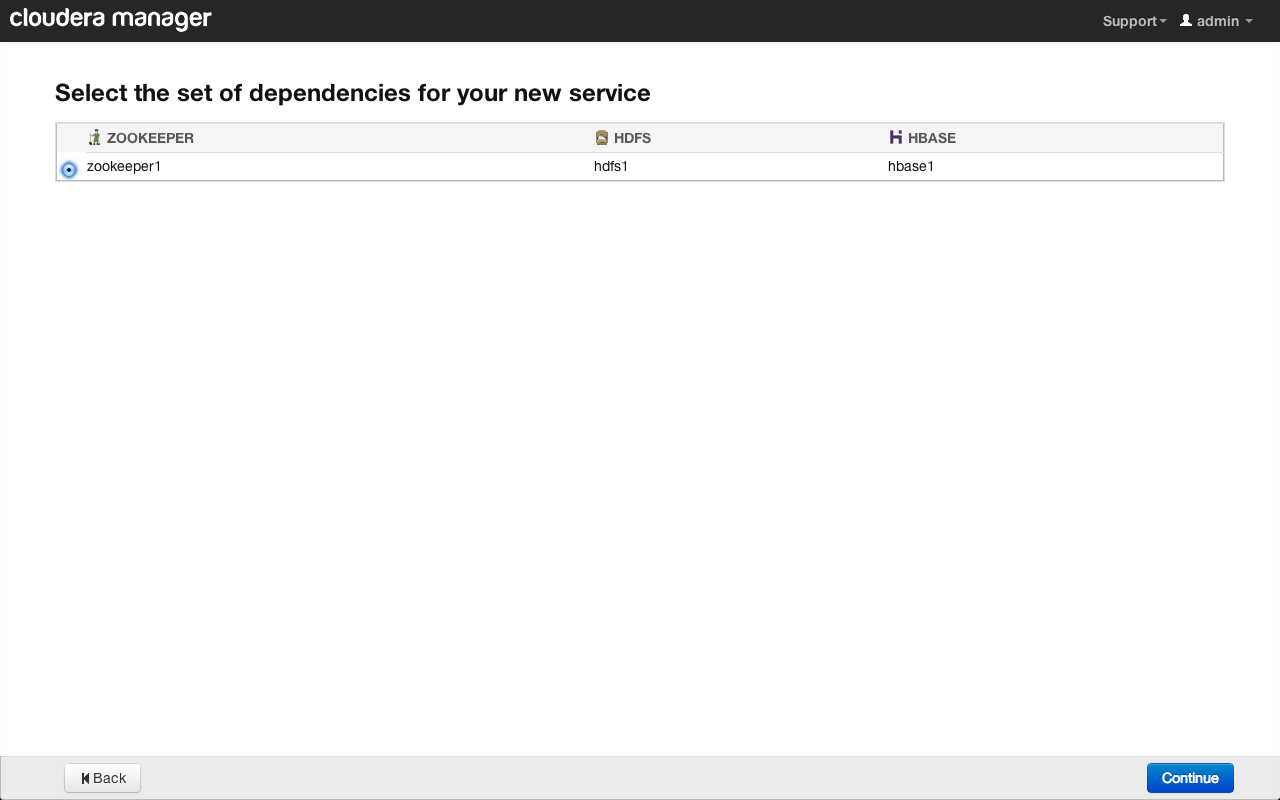
Далее укажем хосты в кластере, на которые будут установлены агенты Flume. Можно настроить несколько независимых сервисов с агентами, расположенными на разных хостах и имеющими разные настройки. В нашем случае мы выберем все доступные хосты:
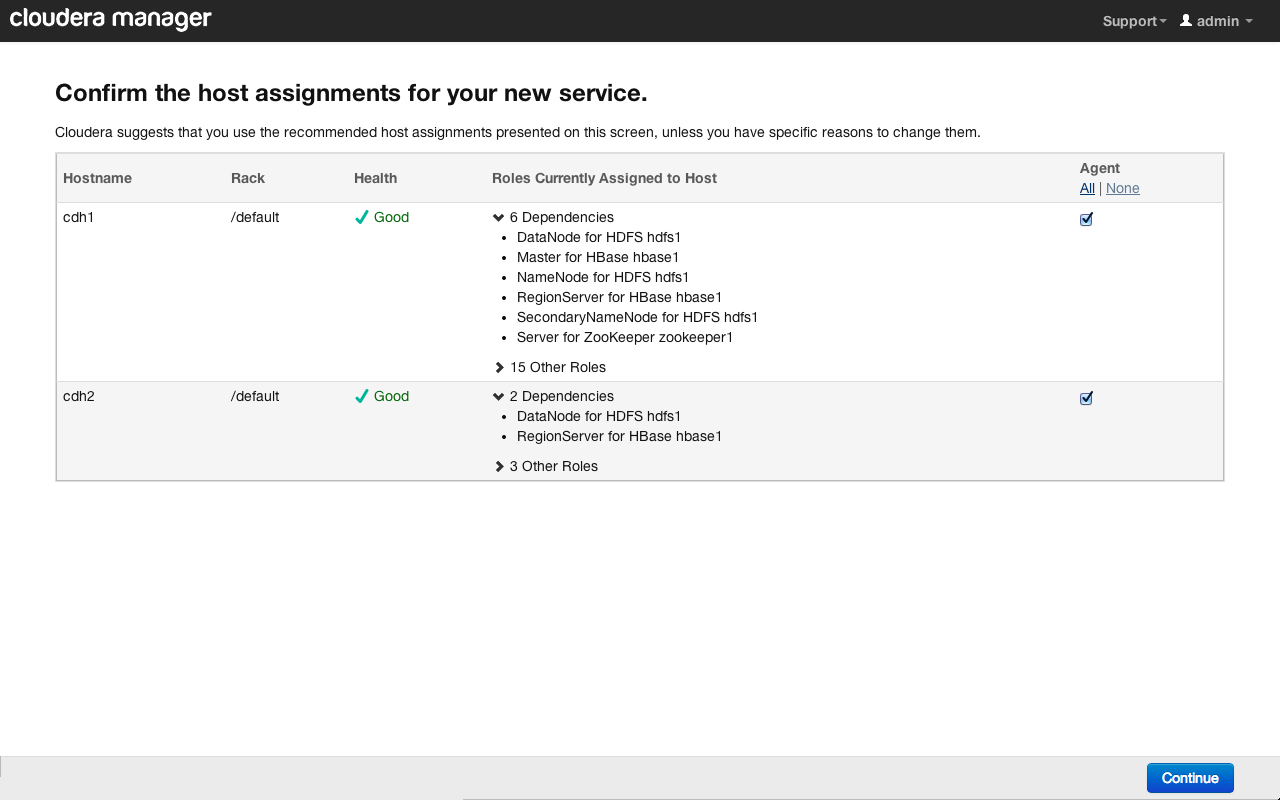
Нажимаем на кнопку «Continue». Вскоре на экране появится сообщение об успешном добавлении нового сервиса:
Теперь перейдем к дашборду Flume, выбрав в Cloudera Manager «Services» → «flume1»:
Откроется страница сервиса, содержащая следующие вкладки: общий статус, инстансы сервиса (в нашем случае в этой вкладке перечислены агенты), команды управления сервисом (включение, выключение, перезагрузка), настройки сервиса, настройки прав доступа, графики статистики и нагрузки. Откроем вкладку настроек «Configurationю → «View and Edit»:
По умолчанию настройки всех агентов Flume хранятся в одном конфигурационном файле (его содержимое отображается в поле Configuration File). Этот файл является общим для всех агентов и наследуется каждым из них:
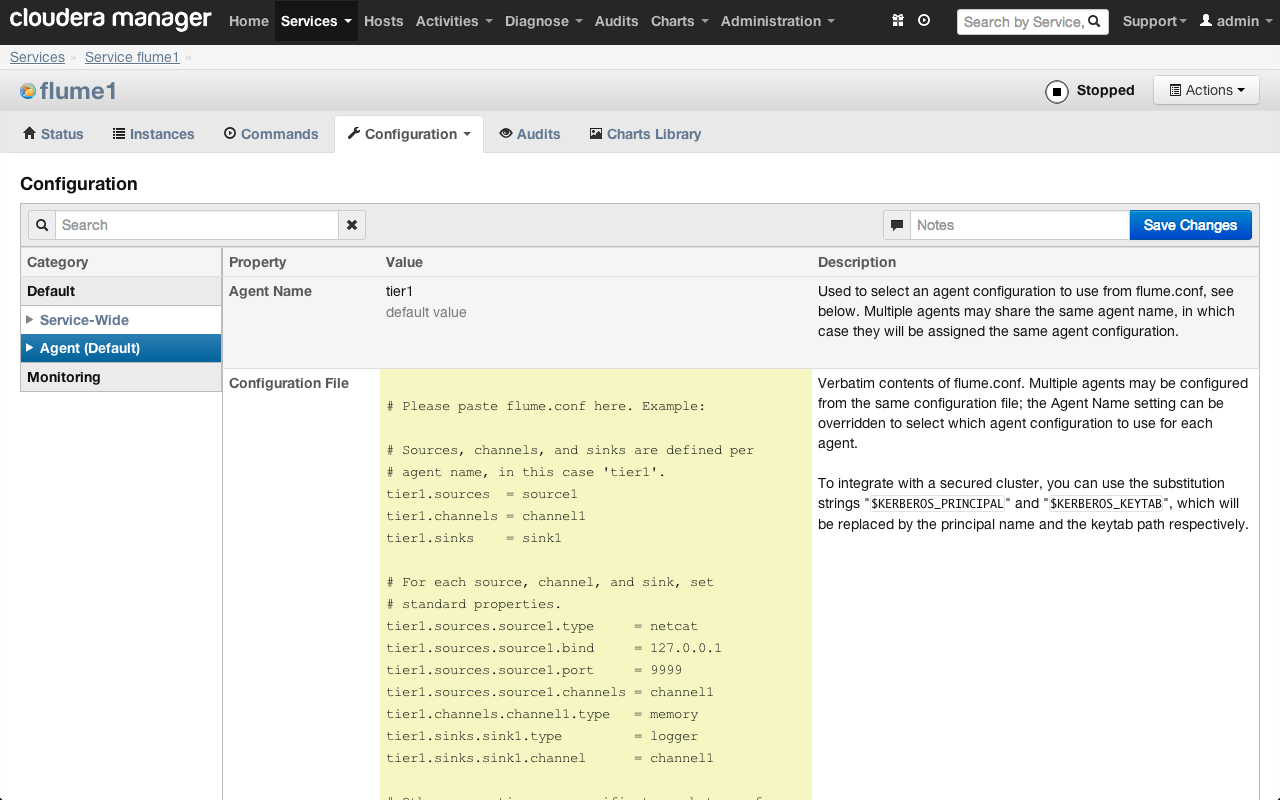
Настройка агента Flume
Рассмотрим пример настройки агента flume, собирающего логи от syslog по UDP и сохраняющего их в HDFS в кластер.
### syslog cfg a1.sources = r1 a1.channels = c1 a1.sinks = k1 # source a1.sources.r1.type = syslogudp a1.sources.r1.port = 5140 a1.sources.r1.host = cdh2.example.com a1.sources.r1.channels = c1 # insert timestamp a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = timestamp # sink a1.sinks.k1.type = hdfs a1.sinks.k1.channel = c1 a1.sinks.k1.hdfs.path = /log/flume/events/%y-%m-%d/%H-%M a1.sinks.k1.hdfs.filePrefix = flume- a1.sinks.k1.hdfs.round = true a1.sinks.k1.hdfs.roundValue = 5 a1.sinks.k1.hdfs.roundUnit = minute a1.sinks.k1.hdfs.fileType = DataStream a1.sinks.k1.hdfs.rollCount = 100000 a1.sinks.k1.hdfs.rollSize = 0 # channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000
Как видно из приведенного выше примера, все записи в файле имеют иерархическую структуру; порядок строк при этом не важен. Перед каждым параметром указывается имя агента, к которому он относится. Далее указывается тип объекта (источник, канал или сток) и его имя, а после этого – типы и подтипы параметров и само значение.
Для всех агентов по умолчанию создается единый файл конфигурации. Благодаря общему файлу конфигурации несколько агентов могут иметь одно и то же имя и, соответственно, один и тот же набор настроек. Это удобно для обеспечения отказоустойчивости агентов или для балансировки нагрузки между ними. Чтобы сменить роль агента, достаточно просто сменить его имя, не переписывая заново конфигурационный файл.
Подробно о настройке Flume-агентов можно прочитать в документации.
Рассмотрим структуру конфигурационного файла более подробно. Сначала мы задаем имена для основных объектов и «привяжем» их к конкретному агенту. В нашем случае мы указываем для агента «a1» источник «r1», канал «c1» и сток «k1»:
a1.sources = r1 a1.channels = c1 a1.sinks = k1
При указании нескольких объектов их имена перечисляются через пробел (например, «а1.sources = r1 r2 r3»)
Начнем с настройки канала. В качестве канала мы используем так называемый memory channel, просто хранящий очередь событий в памяти. На случай непредвиденных всплесков активности максимальный размер очереди установлен в 1000 сообщений, хотя количество сообщений в очереди обычно не превышает 10.
# channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000
Настройка источника Syslog UDP
В качестве источника мы будем использовать UDP Syslog, входящий в стандартную поставку Flume:
a1.sources.r1.type = syslogudp a1.sources.r1.port = 5140 a1.sources.r1.host = cdh2.example.com a1.sources.r1.channels = c1
Параметры type, port и host говорят сами за себя. Параметр channels указывает на каналы, к которым будет подключен источник. При указании нескольких каналов их имена перечисляются через пробел. Название канала указывается без префикса имени агента: подразумевается, что для каждого агента могут использоваться только принадлежащие ему объекты.
Далее указывается объект, о котором следует рассказать более подробно – перехватчик (interceptor). Перехватчики не являются отдельными сущностями, а входят в состав источников.
# insert timestamp a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = timestamp
Составными частями событий (events) в Flume являются тело (непосредственно данные) и дополнительные заголовки, список которых может варьироваться в зависимости от типа источника. Перехватчик осуществляет предварительную обработку данных на лету перед передачей в канал.
Перехватчики могут объединяться в цепочки; они выполняются в соответствии с порядком, указанным в директиве .interceptors (например «a1.sources.r1.interceptors = i1 i2 i3»). В нашем случае используется только один перехватчик «i1» для источника «r1».
Источник syslog записывает в тело события только само сообщение. Все остальные заголовки (соответствующие Syslog RFC) записываются в соответствующие заголовки события Flume.
Источник syslog записывает в заголовок timestamp метку времени не в формате unixtime, а в человекочитаемом виде (например, «2013:09:17-09:03:00»). Чтобы это исправить, мы используем перехватчик timestamp, перезаписывающий заголовок timestamp в формате unixtime. Этот заголовок нам понадобится в настройках стока, о чем пойдет речь далее.
Настройка стока в HDFS
Наконец перейдем к настройке стока, который будет сохранять наши данные в HDFS:
a1.sinks.k1.type = hdfs a1.sinks.k1.channel = c1 a1.sinks.k1.hdfs.path = /log/flume/events/%y-%m-%d/%H-%M a1.sinks.k1.hdfs.filePrefix = flume- a1.sinks.k1.hdfs.fileType = DataStream a1.sinks.k1.hdfs.round = true a1.sinks.k1.hdfs.roundValue = 5 a1.sinks.k1.hdfs.roundUnit = minute a1.sinks.k1.hdfs.rollCount = 100000 a1.sinks.k1.hdfs.rollSize = 0
C параметрами type и channel все ясно, а вот об остальных стоит рассказать подробнее.
В параметре path указывается путь к файлам в HDFS, в которых будут сохранены данные из событий. При сохранении логов очень желательно распределять файлы по подпапкам в соответствии с временной меткой – это упрощает контроль и последующую обработку данных. Достаточно указать каталог с датой и маской, чтобы обработать логи за определенный период. Чтобы сформировать путь к файлу стоку необходима временная метка события, которую мы переопределили ранее с помощью перехватчика.
Параметр filePrefix задает префикс для файлов, который удобно использовать при сборе логов от разных агентов в одни и те же папки.
Параметр fileType задает формат файлов, в которые будут сохранены события. DataStream – это стандартный формат, при котором каждое событие сохраняется как строка в обычном текстовом файле.
Параметры round, roundValue и roundUnit указывают на то, что значение метки времени будет округлено до числа, кратного 5 минутам. Это позволит сохранять файлы в подпапки с шагом в 5 минут. Без этих параметров подпапки создавались бы с шагом в 1 минуту, что не очень удобно.
При работе с большими потоками сообщений представляется целесообразным дополнительно разбивать файлы внутри подпапок, а не писать один огромный файл. Это можно сделать с помощью параметров roll*:
rollCount = 100000 указывает на количество сообщений в одном файле, при превышении которого текущий файл закрывается и создается новый.
rollSize = 0 указывает на то, что мы не ограничиваем размер каждого файла.
Настройка клиента
Итак, наш агент настроен и готов принимать и преобразовывать данные, а затем сохранять их в HDFS. Остается только отправить сами данные через протокол UDP в формате Syslog.
Рассмотрим процедуру сбора данных на примере нашей услуги «Облачное хранилище». В качестве балансировщика нагрузки мы используем haproxy, передающий логи HTTP-запросов агенту Flume. Эти логи содержат адрес клиента, URL запроса, объем переданных данных и другие служебные данные.
Вот пример части конфига haproxy, отвечающей за логирование:
global log [FQDN_Flume_agent]:5140 local0 info maxconn 60000 nbproc 16 user haproxy group haproxy daemon tune.maxaccept -1 tune.bufsize 65536 defaults log global mode http # for hadoop option httplog #option logasap log-format \t%T\t%ci\t%cp\t%ft\t%b\t%s\t%ST\t%B\t%sq\t%bq\t%r option dontlognull #option dontlog-normal
Опция log указывает на адрес сервера и порт, на котором работает агент Flume, а также стандартные для syslog параметры facility local0 и уровень логирования notify.
Директивы mode http и option httplog указывают на то, что мы будем сохранять именно логи доступа по протоколу HTTP. Более подробно о форматах логов haproxy можно прочитать в документации.
Чтобы сохранять максимум информации, отключим опции logasap и dontlog-normal. При отключенной опции logasap haproxy будет логировать HTTP запрос по его завершении с указанием объема полученных и переданных данных. Чтобы haproxy логировал все запросы, в том числе и успешные, нужно отключить опцию dontlog-normal.
Чтобы представить данные в приближенном к машиночитаемому формате и упростить дальнейшую обработку данных, мы изменили форматирование логов (директива log-format). По умолчанию в качестве разделителя в логах используется символ пробела, но он может содержаться и в самих данных, что затрудняет их дальнейшую обработку. Поэтому мы заменили его на символ табуляции. Кроме того, мы отключили кавычки для URL и метода запроса.
Для справки: логи доступа с Хранилища за сутки составляют 20-30Гб. На данный момент мы уже собрали для дальнейшего исследования более 200ТБ данных. Агент Flume практически не нагружает сервер, на котором работает (Load Average ~0.01), а HDFS сервис легко раскладывает и резервирует полученные данные на три независимых узла кластера. И все это – на далеко не самых производительных серверах с обычными шпиндельными дисками.
Заключение
В этой статье мы рассмотрели процедуру сбора и сохранения данных в кластер Hadoop c использованием сервиса Flume на примере логов нашего “Облачного Хранилища”. Естественно, этим примером возможности Flume далеко не исчерпывается.
В следующей статье мы перейдем к самому интересному – обработке данных в Hadoop c помощью инструмента Pig. Stay tuned!




