Реализация пользовательского интерфейса OpenStack LBaaS

При реализации пользовательского интерфейса балансировщика нагрузки для виртуального приватного облака мне пришлось столкнуться с существенными трудностями. Это привело меня к размышлениям о роли фронтенда, чем хочу поделиться в первую очередь. Далее обосновать свои размышления на примере конкретной задачи. Решение задачи получилось, по моему мнению, достаточно творческим и искать его пришлось в сильно ограниченных рамках, поэтому […]

При реализации пользовательского интерфейса балансировщика нагрузки для виртуального приватного облака мне пришлось столкнуться с существенными трудностями. Это привело меня к размышлениям о роли фронтенда, чем хочу поделиться в первую очередь.
Далее обосновать свои размышления на примере конкретной задачи. Решение задачи получилось, по моему мнению, достаточно творческим и искать его пришлось в сильно ограниченных рамках, поэтому думаю, что оно может быть интересным.
Роль фронтенда
Сразу скажу, что не претендую на истину и поднимаю спорный вопрос. Меня несколько удручает иронизирование над фронтендом и вебом в частности, как над чем-то несущественным. И еще больше удручает, что порой это происходит обосновано. Сейчас уже мода спала, но было время, когда все носились с фреймворками, парадигмами и прочими сущностями, громко говорили о том, что все это супер-важно и супер-нужно, а в ответ получали иронию о том, что фронтенд занимается выводом формочек и обработкой кликов на кнопочки, что можно делать и «на коленке».
Сейчас, вроде как, все более-менее пришло в норму. Уже никто особо не стремится рассказать о каждом минорном релизе очередного фреймворка. Мало кто занимается поиском идеального инструмента или подхода, в силу все большего осознания их утилитарности. Но даже это, например, не мешает практически безосновательно ругать Electron и приложения на нем. Я думаю, это происходит из-за непонимания задачи, решаемой фронтендом.
Фронтенд — не просто средство вывода информации, предоставляемой бэкендом, и не просто средство обработки действий пользователя. Фронтенд — нечто большее, нечто абстрактное, а если дать ему простое, четкое определение, то смысл неизбежно потеряется.
Фронтенд находится в некоторых «рамках». Например, в техническом плане он находится между API, предоставляемым бэкендом и API, предоставляемым средствами ввода-вывода. В плане задач, он находится между задачами пользовательского интерфейса, которые решает UX, и задачами, которые решает бэкенд. Таким образом получается довольно узкая специализация фронтенда, специализация прослойки. Это не значит, что фронтендеры не могут оказывать влияние на области за пределами своей специализации, но в тот момент, когда это влияние невозможно, возникает истинная задача фронтенда.
Эту задачу можно выразить через противоречие. Пользовательский интерфейс не обязан соответствовать моделям данных и поведению бэкенда. Поведение и модели данных бэкенда не обязаны соответствовать задачам пользовательского интерфейса. И тогда задача фронтенда заключается в устранении этого противоречия. Чем больше расхождение между задачами бэкенда и пользовательского интерфейса, тем важнее роль фронтенда. И чтобы стало понятно, о чем я говорю, приведу пример, где это расхождение, в силу некоторых причин, оказалось существенным.
Постановка задачи
OpenStack LBaaS, в моем представлении, это программно-аппаратный комплекс средств, необходимых для балансировки нагрузки между серверами. Для меня важно, что его реализация зависит от объективных факторов, от физического отображения. Из-за этого возникают свои особенности в API и в способах взаимодействия с этим API.
При разработке пользовательского интерфейса в первую очередь интересны не технические особенности бэкенда, а его принципиальные возможности. Интерфейс создается для пользователя, а пользователю необходим интерфейс управления параметрами балансировки, и у пользователя нет необходимости погружаться во внутренние особенности реализации бэкенда.
Бэкенд по большей части разрабатывается сообществом, и влиять на его развитие можно в очень ограниченных количествах. Одна из ключевых для меня особенностей заключается в том, что разработчики бэкенда готовы жертвовать удобством и простотой средств управления в угоду производительности, и это абсолютно оправдано, так как речь идет о балансировке нагрузки.
Есть еще один тонкий момент, и сразу хочу его обозначить, предупреждая некоторые вопросы. Понятно, что на OpenStack и их API свет клином не сошелся. Всегда можно разработать свой комплекс средств или «прослойку», которая будет работать с API OpenStack, выдавая собственное API, удобное для задач пользователя. Вопрос только в целесообразности. Если изначально имеющиеся средства позволяют реализовать интерфейс пользователя таким, каким он был задуман, то имеет ли смысл плодить сущности?
Ответ на этот вопрос многогранен и для бизнеса будет упираться в разработчиков, в их занятость, в их компетенции, в вопросы об ответственности, поддержки и так далее. В нашем случае целесообразнее всего было решить часть задач на фронтенде.
Особенности OpenStack LBaaS
Я хочу обозначить лишь те особенности, которые оказали сильное влияние на фронтенд. Вопросы, почему эти особенности возникли или на что они опираются, уже выходят за рамки данной статьи.
Я работаю с готовой документацией и вынужден принимать ее особенности. Кому интересно, что представляет из себя OpenStack Octavia изнутри, может ознакомиться с официальной документацией. Octavia – это название комплекса средств, созданного для балансировки нагрузки в экосистеме OpenStack.
Первая особенность, с которой я столкнулся по ходу разработки, — это большое количество моделей и связей, необходимых для отображения состояния балансировщика. В API Octavia описано 12 моделей, но для клиентской части необходимо всего 7. Эти модели обладают связями, часто денормализованными, на изображении ниже представлена примерная схема:
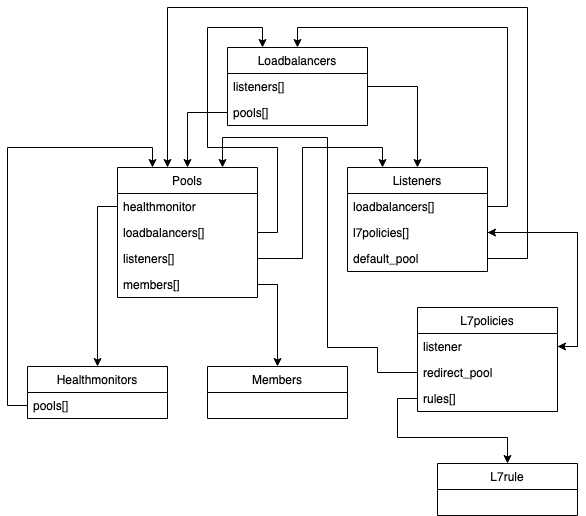
«Семь» звучит не очень внушительно, но в действительности, для обеспечения полноценной работы интерфейса, на момент написания этого текста, мне пришлось задействовать 16 моделей данных и около 30 отношений между ними. Так как Octavia — это только балансировщик, для его работы необходимы другие модули OpenStack. И все это нужно всего лишь для двух страниц в пользовательском интерфейсе.
Вторая и третья особенности заключаются в асинхронности и транзакционности работы Octavia. У моделей данных есть поле статуса, которое отражает состояние операций, производимых над объектом.
| Статус | Описание |
|---|---|
| ACTIVE | Объект в нормальном состоянии |
| DELETED | Объект удален |
| ERROR | Объект поврежден |
| PENDING_CREATE | Объект в процессе создания |
| PENDING_UPDATE | Объект в процессе обновления |
| PENDING_DELETE | Объект в процессе удаления |
Операция чтения объекта происходит синхронно и не имеет ограничений. Но операции создания, обновления и удаления могут занимать неопределенное количество времени. Это связано именно с тем, что модели данных имеют, грубо говоря, физический смысл.
После отправки запроса на создание мы можем знать, что запись появилась, можем ее прочитать, но до полноценного завершения операции создания мы не можем производить над этой записью каких-либо других операций. Любая такая попытка будет приводить к ошибке. Операцию изменения объекта можно инициировать, только когда объект находится в статусе ACTIVE, отправить объект на удаление можно в статусах ACTIVE и ERROR.
Эти статусы могут приходить по WebSockets, что очень облегчает их обработку, но гораздо большей проблемой являются транзакции. При внесении изменений в какой-либо объект, в транзакции также будут участвовать и все связанные модели. Например, при внесении изменений в Member, заблокированными окажутся связанные с ним Pool, Listener и Loadbalancer.
Так выглядит это с точки зрения событий, получаемых по веб-сокетам:
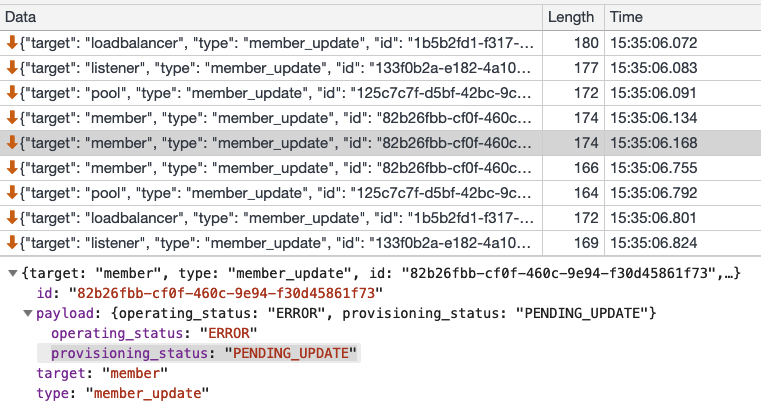
- первые четыре события — это перевод объектов в статус PENDING_UPDATE: в поле target содержится имя модели объекта, участвующего в транзакции;
- пятое событие — это просто дубликат (не знаю, с чем он связан);
- последние четыре — это обратный перевод в статус ACTIVE. В данном случае это операция изменения веса, и занимает она меньше секунды, но иногда бывает, что требуется гораздо больше времени.
Еще на скриншоте можно наблюдать, что порядок событий не обязательно должен быть строгим. Таким образом получается, что для инициирования какой-либо операции необходимо знать не только статус самого объекта, но и статусы всех зависимостей, которые также будут участвовать в транзакции.
Особенности пользовательского интерфейса
Теперь представьте себя на месте пользователя, которому необходимо откуда-то знать, что для организации балансировки между двумя серверами:
- Надо создать слушателя, в котором будет определен алгоритм балансировки.
- Создать пул.
- Назначить пул слушателю.
- Добавить в пул ссылки на балансируемые порты.
Каждый раз необходимо дожидаться завершения операции, которое зависит от всех ранее созданных объектов.
Как показало внутреннее исследование, в представлении обычного пользователя есть только примерное осознание того, что у балансировщика должна быть точка входа, должны быть точки выхода и параметры осуществляемой балансировки: алгоритм, вес и прочие. Пользователь не обязан знать, что такое OpenStack.
Не знаю, насколько сложным для восприятия должен быть интерфейс, где за всем техническими особенностями бэкенда, описанными выше, необходимо следить самому пользователю. Для консоли это может быть допустимо, так как ее использование предполагает высокий уровень погружения в технологию, но для веба такой интерфейс является ужасом.
В вебе пользователь ждет, что заполнит одну ясную и логичную форму, нажмет одну кнопку, подождет и все заработает. Наверное, с этим можно поспорить, однако предлагаю сконцентрироваться на особенностях, влияющих на реализацию фронтенда.
Интерфейс был спроектирован таким образом, что предполагает каскадное использование операций: одно действие в интерфейсе может предполагать осуществление нескольких операций. Интерфейс не предполагает, что пользователь может производить действия, которые в данный момент невозможны, однако интерфейс предполагает, что пользователь должен понимать, почему это так.
Интерфейс является единым целым, а следовательно, отдельные его элементы могут использовать информацию от разных зависимых сущностей, включая мета-информацию.
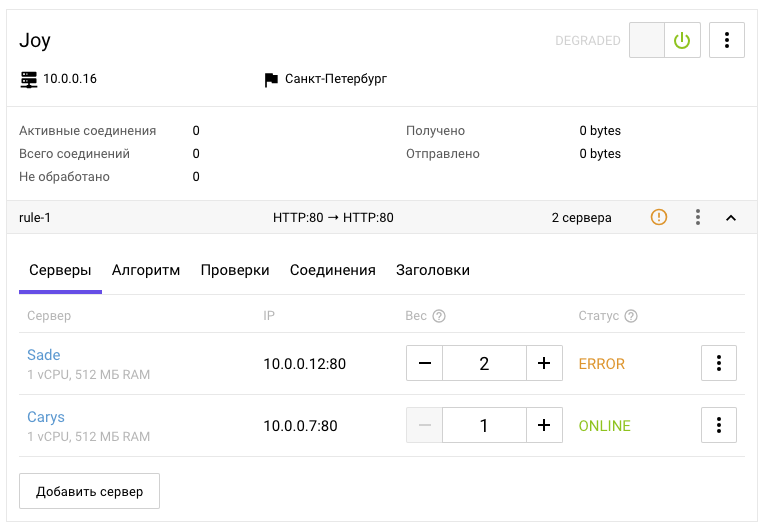
Если принять в учет, что есть некоторые особенности интерфейса, свойственные не только балансировщику, такие как переключатели, аккордеоны, табы, контекстное меню и предположить, что их принципы работы ясны изначально, то думаю, для пользователя, представляющего, что такое балансировка нагрузки, не составит большого труда прочитать большую часть интерфейса выше и сделать предположение о том, как им управлять. Но вот выделить, какие части интерфейса скрываются за моделями балансировщика, слушателя, пула, мембера и прочими сущностями, — уже не самая очевидная задача.
Устранение противоречий
Надеюсь, мне удалось показать, что особенности бэкенда плохо ложатся на интерфейс, и что эти особенности не всегда могут быть устранены со стороны бэкенда. Вместе с этим особенности интерфейса плохо ложатся на бэкенд, и тоже не всегда могут быть устранены, без усложнения интерфейса. Каждая из этих областей решает свои задачи. В зоне ответственности фронтенда находится задача устранения проблем для обеспечения необходимого уровня взаимодействия между интерфейсом и бэкендом.
Я в своей практике сразу бросился в омут с головой, не обратив внимания, точнее даже не попытавшись выяснить те особенности, что выше, но мне повезло либо опыт помог (и был выбран правильный вектор). Уже неоднократно замечал за собой, что при использовании стороннего API или библиотеки очень полезно предварительно ознакомиться с документацией: чем подробнее, тем лучше. Документации часто похожи друг на друга, люди все же опираются на опыт других людей, но там есть и описание особенностей каждой отдельной системы, и оно содержится в деталях.
Если бы я изначально потратил пару дополнительных часов на изучение документации, а не выдергивал необходимую информацию по ключевым словам, у меня возникли бы мысли о проблемах, с которыми придется столкнуться, и это знание могло бы оказать влияние на архитектуру проекта еще на самых ранних этапах. Возвращение назад для устранения ошибок, совершенных в самом начале, очень деморализует. А без полного контекста возвращаться порой приходится несколько раз.
Как вариант, можно гнуть свою линию, постепенно генерируя все больше и больше кода «с душком», но чем больше будет эта куча кода, тем больнее ее будет разгребать в итоге. При проектировании архитектуры, конечно, тоже не стоит сильно глубоко погружаться, учитывать все возможные и невозможные варианты, тратя на это огромное количество времени, важно искать баланс. Но более-менее подробное знакомство с документацией часто оказывается очень полезным вложением не очень большого количества времени.
И тем не менее, с самого начала увидев большое количество задействованных моделей, я понял, что необходимо будет построить отображение состояние бэкенда на клиент с сохранением всех связей. Уже после того как у меня получилось вывести всю необходимую информацию на клиенте, со всеми связями и так далее, потребовалось организовать очередь задач.
Данные обновляются асинхронно, доступность операций определяется множеством условий, и когда требуется каскадное выполнение операций, без очереди в таких условиях не обойтись. Пожалуй, в двух словах, это и есть вся архитектура моего решения: хранилище с отражением состояния бэкенда и очередь задач.
Архитектура решения
Из-за неопределенного количества моделей и связей я заложил в структуру хранилища возможность масштабирования, сделав это с помощью фабрики, которая возвращает декларативное описание коллекций хранилища. У коллекции есть сервис, простой класс модели с CRUD. Можно было бы в модели вынести и описание связей, как это делается, например, в RoR или в старом добром Backbone, но это потребовало бы изменения большого количества кода. Поэтому описание связей лежит рядом с классом модели:

Всего у меня получилось 2 типа связей: один к одному, один ко многим. Также можно описать обратную связь. Помимо типа указывается коллекция зависимости, поле, к которому прикрепляется найденная зависимость и поле, из которого считывается ID зависимого объекта (в случае связи один ко многим считывается список ID). Если у объектов условие связи сложнее, чем простые ссылки на объекты, то в фабрике можно описать функцию тестирования двух объектов, по результатам работы которой будет определяться наличие связи. Выглядит все это немного «велосипедно», но работает без лишних зависимостей и именно так, как нужно.
У хранилища есть модуль ожидания добавления и удаления ресурса, по сути это — обработка одноразовых событий с проверкой по условию и с интерфейсом промиса. При подписке передается тип события (добавление, удаление), функция тестирования и обработчик. При наступлении определенного события и при положительном результате тестирования выполняется обработчик, после чего отслеживание прекращается. Событие может наступить при подписке синхронно.
Использование такого паттерна позволило автоматически проставлять сколь угодно сложные связи между моделями, и делать это в одном месте. Это место я назвал трекер. Он при добавлении какого-либо объекта в хранилище начинает отслеживание его связей. Модуль ожидания позволяет реагировать на события и производить проверку наличия связи между отслеживаемым объектом и объектом, попавшим в хранилище. Если объект уже присутствовал в хранилище, то модуль ожидания вызывает обработчик незамедлительно.
Такое устройство хранилища позволяет описать любое количество коллекций и связей между ними. При добавлении и удалении объектов хранилище автоматически проставляет либо сбрасывает свойства с содержанием зависимых объектов. Плюсы такого подхода в том, что все связи описаны явным образом, а их отслеживанием и актуализацией занимается одна система; минусы — в сложности реализации и отладке.
В целом, такое хранилище достаточно тривиально и мной было сделано самостоятельно, потому что встраивать в имеющуюся кодовую базу готовое решение было бы гораздо сложнее, но еще сложнее к готовому решению было бы приделать очередь задач.
Все задачи, как и коллекции, имеют декларативное описание и создаются фабрикой. Задачи могут иметь в описании условия для запуска и список задач, которые необходимо будет добавить в очередь после выполнения текущей.
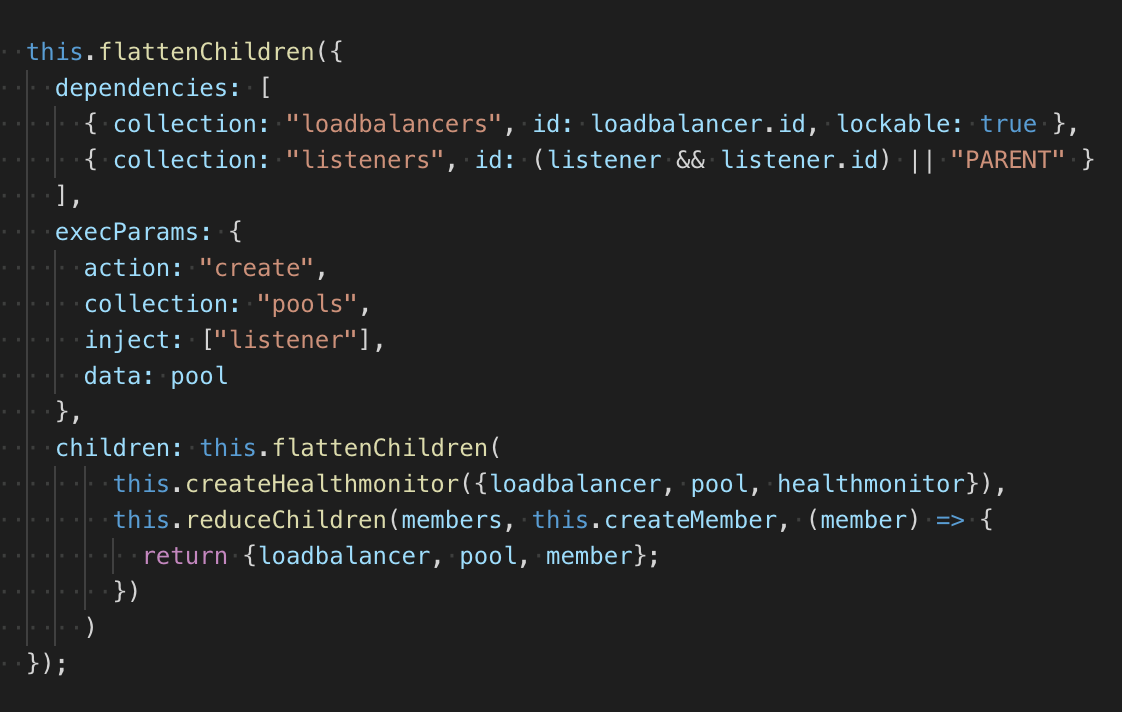
В примере выше описывается задача на создание пула. В зависимостях указан балансировщик и слушатель, по умолчанию происходит проверка на статус ACTIVE. Объект балансировщика является блокируемым, так как обработка задач в очереди может происходить синхронно, блокировка позволяет избежать конфликтов в моменте, когда запрос на выполнение был отправлен, но статус еще не поменялся, однако предполагается, что он поменяется. Вместо PARENT в случае если пул создается в результате выполнения каскада задач, ID будет подставлен автоматически.
После создания пула в очередь будут добавлены задачи на создание монитора доступности и создание всех членов этого пула. На выходе получается структура, которую полностью можно преобразовать в JSON. Сделано это для возможности восстановления очереди в случае сбоя.
Очередь на основе описания задач самостоятельно отслеживает все изменения в хранилище и проверяет условия, выполнение которых необходимо для запуска задачи. Как я уже говорил, статусы приходят по веб-сокетам, и генерировать необходимые события для очереди в таком случае очень просто, но в случае необходимости не будет проблемой приделать механизм обновления данных по таймеру (изначально это закладывалось в архитектуру, так как веб-сокеты по разным причинам могут работать не очень стабильно). После выполнения задачи очередь автоматически сообщает хранилищу о необходимости обновления связей в заданных объектах.
Заключение
Потребность масштабируемости привела к декларативному подходу. Потребность в отображении моделей и связей между ними привела к единому хранилищу. Потребность в обработке зависимых объектов привела к очереди.
Объединение этих потребностей, возможно, не самая простая задача в плане реализации (но это уже отдельный вопрос). А вот в плане архитектуры решение очень простое и позволяет устранить все противоречия между задачами бэкенда и пользовательским интерфейсом, наладить их взаимодействие и заложить фундамент под другие возможные особенности любой из сторон.
Со стороны панели управления Selectel процесс балансировки прост и понятен, что позволяет заказчикам услуги не тратить ресурсы на самостоятельную реализацию балансировщика, сохранив при этом возможность гибко управлять трафиком.
Попробуйте наш балансировщик в действии уже сейчас и напишите свой отзыв в комментариях.




