

Развивают такое ML- и Data-многообразие около 30 Data Science-специалистов и 15 разработчиков. Сегодня в продакшене запущено более 150 моделей — около 300 с учетом реплик.
Меня зовут Денис Брандес, я инженер-программист в Контуре. В этой статье поделюсь конспектом своего доклада и расскажу, как наша команда справляется с сервингом сотни моделей и какие решения мы для этого разработали.
Если вам интересна тема статьи, присоединяйтесь к сообществу «MLечный путь» в Telegram. Там мы вместе обсуждаем проблемы и лучшие практики организации production ML-сервисов, а также делимся собственным опытом. А еще там раз в неделю выходят дайджесты по DataOps и MLOps.
С чего все начиналось
Контур занимается разработкой SaaS-решений для бизнеса, которые помогают организовать интернет-отчетность и онлайн-бухгалтерию. Среди продуктов компании — сервисы для ЭДО и работы с маркировкой, облачного товароучета, онлайн-кассы и другое.
Центр AI зародился в Контуре около семи лет назад. Тогда в команде было всего четыре Data Science-специалиста, два разработчика и менее десяти моделей в продакшене, которые сервились, в лучшем случае, на виртуальных машинах. Для разработки использовались только jupyter-ноутбуки, а инструментов для мониторинга работы моделей не было вовсе.

Была довольно линейная и предсказуемая модель работы: Data Science-специалист тюнил модель, передавал разработчику, который затем ее оборачивал в REST-сервис и сдавал заказчику.
Первые проблемы и решения
Поначалу Data Science был не самостоятельным направлением в компании, а скорее усилием отдельных энтузиастов, которые предлагали решать с его помощью различные проблемы. Но времена менялись, появлялись все более важные задачи, а моделей и сотрудников становилось больше. Нужно было быстро масштабироваться, деплоить больше моделей и делать это быстрее.
И тут мы столкнулись с первыми проблемами.
- Деплой модели был полностью ручной операцией, для которой нужно было привлекать разработчика. Коммуникация между разработчиком и дата-сайентистом занимала много времени, в результате на деплой каждой модели уходило около двух недель.
- Сервисы с моделями во многом были похожи, но все же отличались. В силу их специфичности возникали проблемы с поддержкой. То же самое с API: периодически у заказчиков появлялись все новые и новые вопросы по интеграции.
- тсутствовали инструменты для мониторинга моделей. Они просто сервились, а что происходит с моделью в проде — было загадкой ящика Пандоры. А если мониторинг и был, то слишком точечным и редким.
Решение — сервис для хостинга моделей
Мы решили, что нам нужен единый сервис, который позволит управлять хостингом моделей, и сформировали к нему требования.
- Деплой модели должен занимать один день. Это позволит нам значительно снизить общий time-to-market наших моделей.
- Деплой — типовая операция. Для стандартного деплоя модели не нужно привлекать разработчика.
- Должен быть единообразный API для доступа к моделям, который можно легко интегрировать и описывать на разных языках программирования. Последнее было особенно важно, потому что у всех заказчиков свой стек технологий.
- Нужны инструменты для observability наших решений. Притом они должны быть «из коробки», чтобы можно было задеплоить модель и легко получить инструменты для ее поддержки.
Семь лет назад термин MLOps либо не существовал, либо о нем почти никто не слышал. Список доступных open-source решений тоже был сильно меньше. Таким образом, мы не нашли готового решения и сделали свое на базе Kubernetes и Aiohttp. К нему прикрутили собственное API для доступа ко всем моделям и сделали единую «обертку», которая запускает их в виде сервиса.
В результате наш сервис для хостинга моделей стал единым местом, через которое мы стали управлять ML-моделями. С его помощью можно задеплоить или удалить модель, изменить ее параметры и т. д.
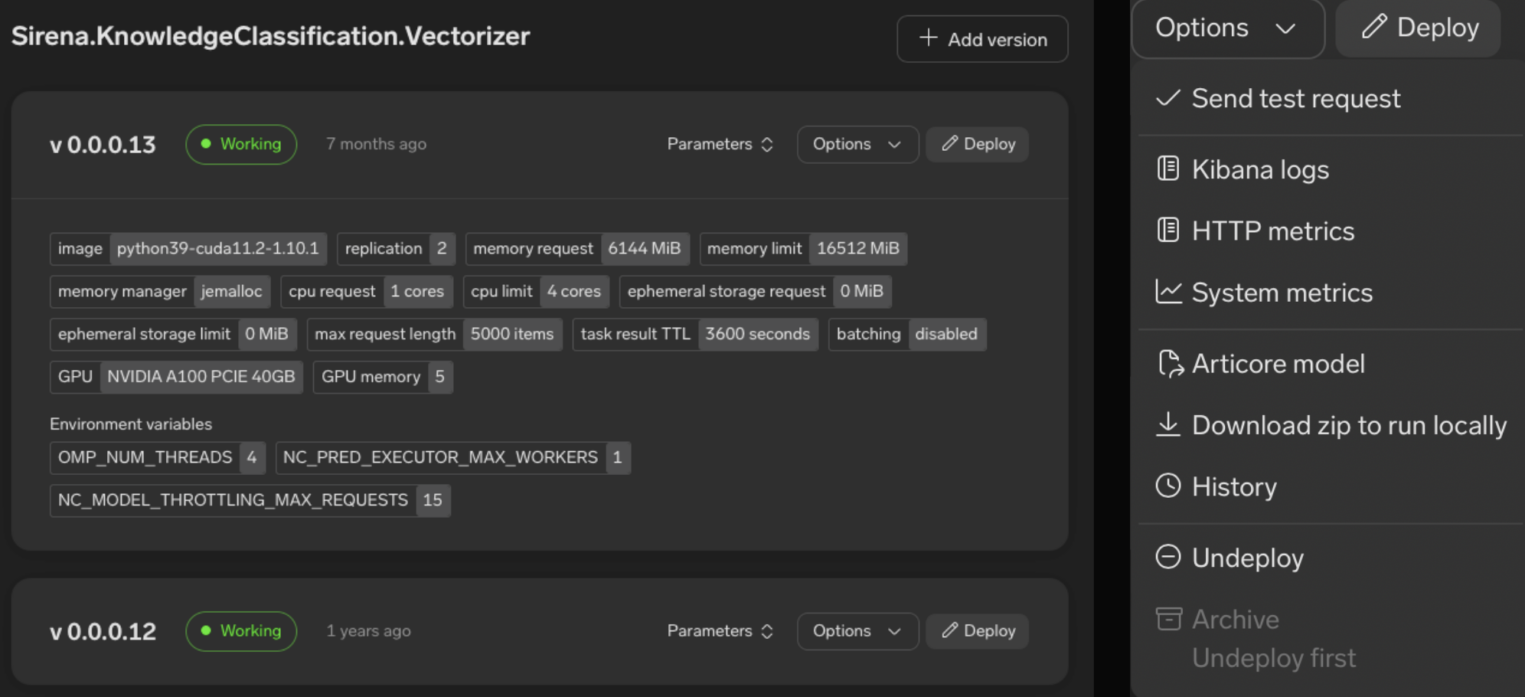
Выше — пример того, как выглядит веб-интерфейс нашего сервиса. Видно, какие параметры использует ML-модель, сколько потребляет виртуальных ресурсов и какие настройки у виртуального окружения. Правее — окно, в котором можно перейти и посмотреть логи с метриками модели, отправить тестовый запрос и задеплоить новую версию.
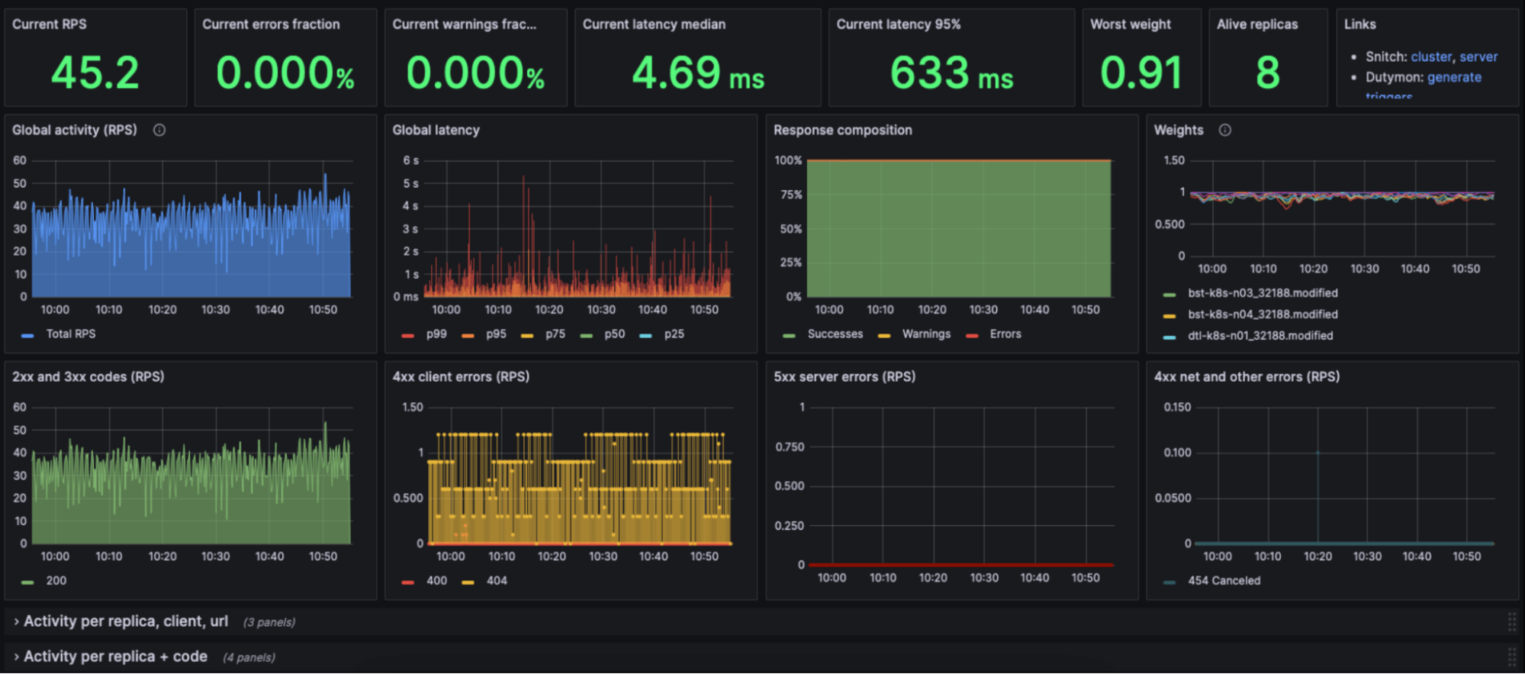
В отдельном окне можно мониторить метрики модели — например, посмотреть, как быстро она обрабатывает запросы, различные перцентили, количество реплик и т. д.
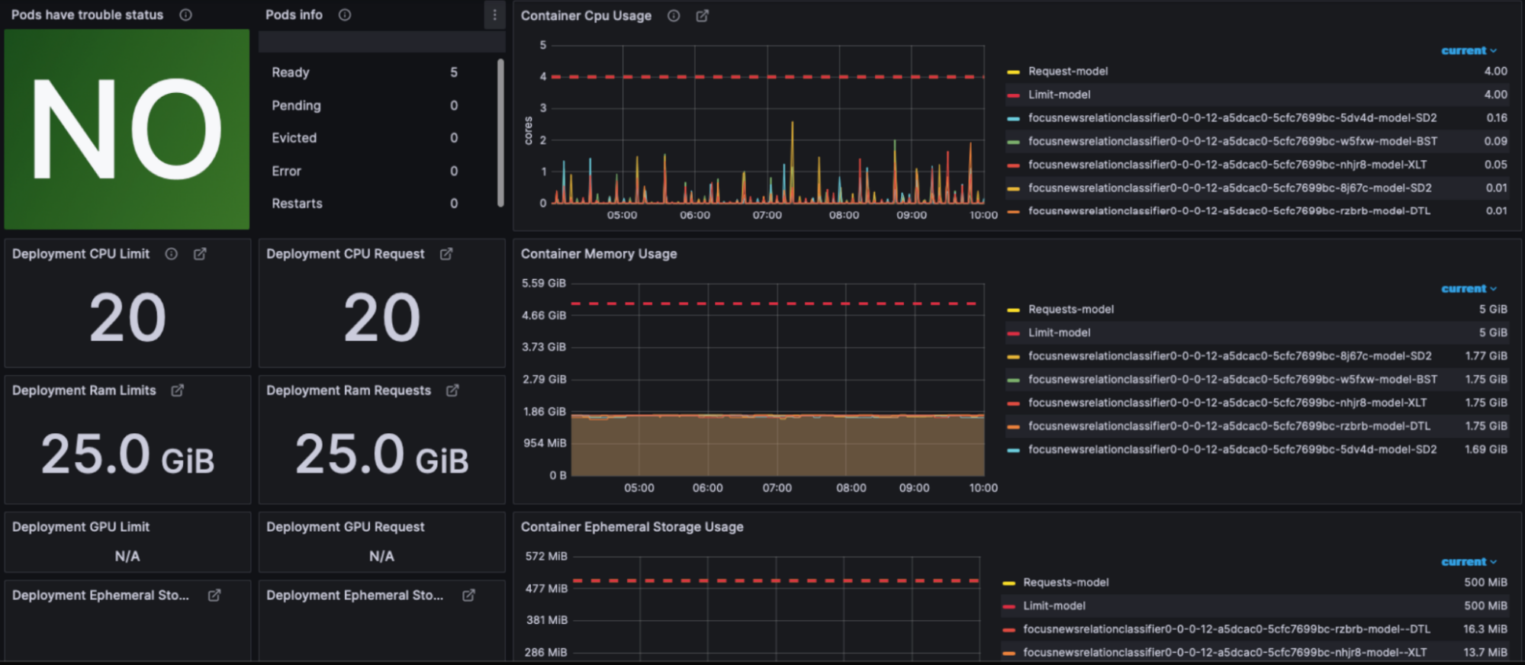
В отдельной вкладке можно посмотреть, сколько GPU, CPU и других ресурсов потребляет система. Для сбора этих показателей мы используем Prometheus, а для визуализации — Grafana.
Определение параметров модели
С появлением сервиса для хостинга моделей мы договорились, что Data Science-специалисты теперь будут самостоятельно деплоить модели в продакшен. Однако мы столкнулись с проблемой: им достаточно тяжело определить необходимые параметры для деплоя. Например, ресурсы процессора, видеокарты и памяти, которые будет использовать модель, количество реплик, батчинг, троттлинг запросов, асинхронный инференс и другие параметры.
Решение — типовой сценарий
Чтобы решить эту проблему, мы определили простой типовой сценарий. То есть собрали базовые правила, к которым можно обратиться для определения параметров деплоя.
- У модели должно быть минимум две реплики для отказоустойчивости. Если есть определенные требования по нагрузке, реплик может быть больше.
- Требуемые ресурсы определяются только моделью. Наш сервис имеет низкий overhead, поэтому его требования не нужно принимать в расчет.
- Чтобы качественно определить параметры модели, необходимо провести нагрузочное тестирование с помощью специальных инструментов. Если не получается, можно позвать разработчика, который обязательно поможет.
Эти правила помогают определить набор параметров модели для большинства стандартных сценариев.
Инструмент для нагрузочного тестирования
Нагрузочное тестирование не так сложно провести, если под рукой есть готовый набор инструментов. Для этой задачи мы выбрали достаточно популярную Python-библиотеку Locust, поверх которой написали обертку. Она позволяет в виде сценария описать необходимый профиль нагрузки и подать его на приложение.
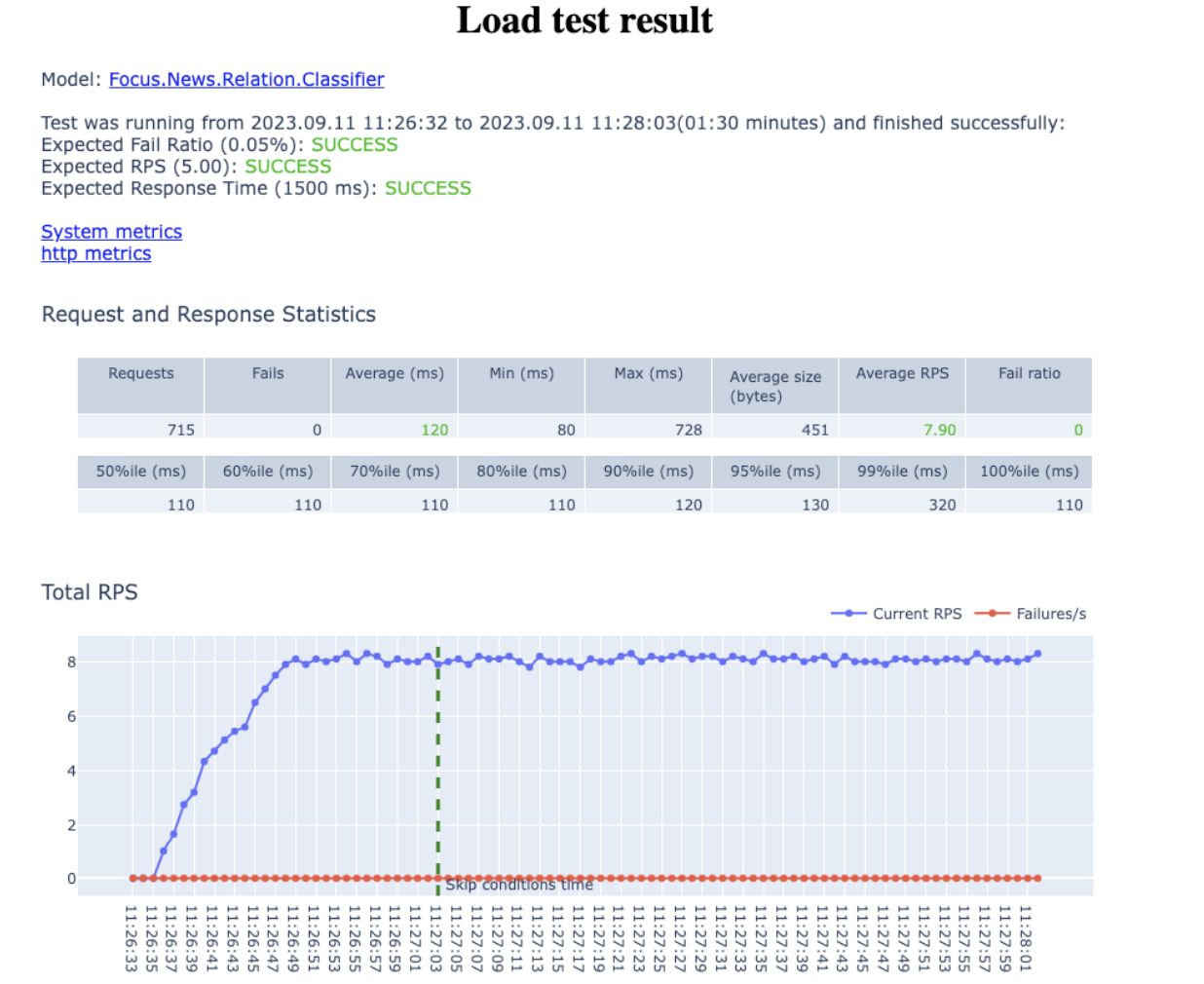
По бенчмаркам можно также посмотреть, насколько эффективно модель задействует или утилизирует ресурсы. Процесс нагрузочного тестирования итеративный, поэтому для получения репрезентативных результатов его нужно прогнать три-четыре раза.
Алгоритм из нескольких шагов
Дата-сайентисты теперь могут самостоятельно деплоить модели и определять их параметры. Однако далеко не в каждом сценарии достаточно «сходить в модель и получить ответ». Часто бывает, когда нужно дополнительно выполнить, например, трансформацию данных или сходить в какой-то источник и получить данные для обогащения запроса, либо для получения итогового результата нужно последовательно сходить в несколько моделей.
Во всех таких сценариях настройка вспомогательной логики выполнялась на стороне вызывающего сервиса. Соответственно, Data Science-специалисту нужно было договориться с разработчиком сервиса, чтобы он реализовал необходимую логику на своей стороне. И так при каждом изменении.
Решение — сервис для написания алгоритмов
Мы решили дать дата-сайентистам возможность самостоятельно настраивать такие «алгоритмы» из нескольких шагов. Для этого мы реализовали сервис, который позволяет определить набор блоков (запросами в модели, базы данных, трансформациями) и связи между ними. А также — логировать данные на входе и выходе каждого блока и проводить A/B-тесты.
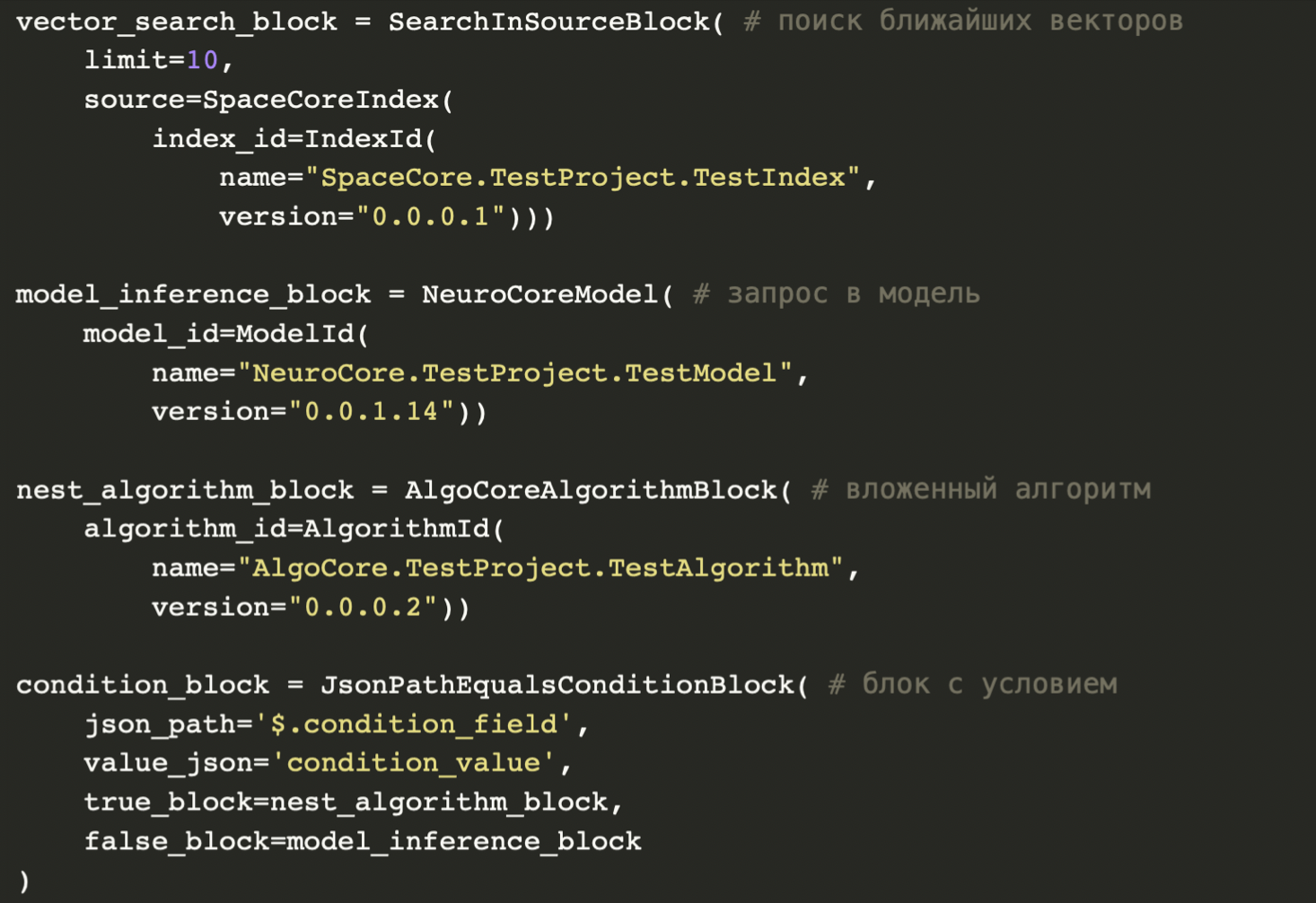
Вот как выглядит описание алгоритма на Python. Первый блок ищет ближайшие векторы в базисе, второй — делает запрос в модель, третий — во вложенный алгоритм, а четвертый — вызывает следующий блок в зависимости от условия. Это упрощенный и концептуальный пример. На самом деле, у интерфейсов гораздо больше параметров, но каркас выглядит так.
Изменение зон ответственности
Давайте вспомним, как выглядела схема работы дата-сайентиста в самом начале, и посмотрим, как изменились зоны ответственности специалистов после интеграции сервисов.
Что теперь делает Data Science-специалист
Изначально Data Science-специалист занимался только обучением модели — для вывода ее в прод нужен был разработчик. Теперь он способен самостоятельно вывести модель в прод, а также:
- определять параметры моделей,
- тестировать модели,
- деплоить модели,
- писать алгоритмы для сложных сценариев,
- мониторить работу моделей и поддерживать их.
Что делает разработчик
Разработчики больше не являются обязательными участниками процесса деплоя модели и ее поддержки. Их основная задача — дать дата-сайентисту все необходимые инструменты для самостоятельного управления процессом от этапа эксперимента до деплоя модели в прод.
Чем теперь занимается типичный разработчик в нашей команде:
- создает и поддерживает инструменты для Data Science-специалистов;
- участвует в разработке сложных сценариев, которые не укладываются в типовые инструменты;
- дежурит и реагирует на алерты.
Мы не утверждаем, что такое распределение зон ответственностей идеально и подходит для всех команд. Но мы в нашем отделе пришли к такому разделению и этот процесс работает. Если у вас есть вопросы, предложения или советы из своей практики, поделитесь в комментариях.
Чего не хватает
Сейчас у нас нет плавного процесса от эксперимента до деплоя модели. Это два разобщенных шага, единственное звено между ними — Data Science-специалист.
Кроме того, отсутствует автоматический запуск нагрузочных тестов. Испытать модель можно только вручную, а хотелось бы делать это автоматически по различным триггерам, например, при деплое новой версии модели.
Также нам не хватает автоскейлинга моделей. Специалисты вынуждены пристально мониторить потребляемые ресурсы и масштабировать их при необходимости. Это усугубляется тем, что часто ресурсы потребляются неоптимально. До сих пор встречаются ситуации, когда для модели было запрошено десять ядер, а спустя время мы узнаем, что система использовала меньше пяти. Пока эти проблемы решаются вручную, но на таком масштабе это сложно и неэффективно. Сейчас мы исследуем различные варианты автокейлинга именно для моделей.
Текущие планы
Если вам интересно, какие инструменты мы планируем внедрить, чтобы доработать сервис и оптимизировать пайплайн, смотрите запись доклада. В конце мы поделились стеком технологий для начинающих MLOps-инженеров.




