

Что такое отказоустойчивая IT-инфраструктура
Отказоустойчивая IT-инфраструктура — это совокупность технологий, методов и процессов, которые обеспечивают непрерывную работу систем даже в нештатных ситуациях — например, при неисправности, сбое или отказе оборудования, программного обеспечении и других составляющих инфраструктуры.
Классический пример отказоустойчивости — распределенная IT-инфраструктура, которая построена на нескольких серверах, расположенных в разных регионах. Так, например, при «падении метеорита» на один регион, сохраняется второй. И если на серверах был запущен веб-сервис, он продолжит работать.
Другой пример — сетевое резервирование. Среди клиентов Selectel — социальные сети, интернет-издания, системы электронных платежей и другие компании. Их сервисы нуждаются в бесперебойной работе, которая достигается сетевым резервированием в дата-центрах (ЦОД’ах).
Сетевое резервирование предполагает, что все данные будут гарантированно доставлены из точки A в точку B. Например, если нужно организовать связность между двумя дата-центрами, инженер может проложить два кабеля по разным физическим маршрутам. Тогда если один находился рядом с вулканом и сгорел во время извержения, второй продолжит функционировать на дне океана.
Все это — примеры отказоустойчивой инфраструктуры. Но примеров на деле больше, чем мы разобрали — погрузимся в вопрос глубже.
Построение отказоустойчивой инфраструктуры
Основная цель при организации отказоустойчивой IT-инфраструктуры — минимизировать влияние отказов на бизнес-процессы и обеспечить доступность данных и приложений для пользователей.
Инженерные системы дата-центра
Современные дата-центры обязаны отвечать высоким требованиям отказоустройчивости. Чтобы добиться желаемого уровня, сначала необходимо резервировать непосредственно самые «приземленные» в этой цепочке процессы, такие как электричество и кондиционирование.
Хороший пример
В наших дата-центрах установлены источники бесперебойного питания и дизель-генераторы, которые позволяют не зависеть от нагрузок и выключения света. Даже если весь город обесточат, это никак не отразится на работе ваших сервисов.
Для поддержания оптимальной температуры в машинных залах мы используем разные системы: фреоновые, чиллерные и фрикулинг с охлаждением внешним воздухом. Все системы зарезервированы по схеме N+2.
Подробнее о резервировании инженерных систем →
Административные процессы
Какой бы технически надежной ни была архитектура сервиса, всегда есть вероятность возникновения неисправностей, которые могут плохо сказаться на работе сервисов и компании в целом. Поэтому в любой инфраструктуре важно наладить административные процессы, чтобы всегда была команда, которая будет следить за работой IT-систем.
Есть два варианта: использовать on-premise и нанять собственных людей или арендовать инфраструктуру у провайдера, который не скупится на квалифицированных специалистах. Выбор зависит от ситуации и потребностей компании.
Хороший пример
За питанием и охлаждением в Selectel следят инженеры. Они же обслуживают оборудование. Сетевые инженеры круглосуточно мониторят сетевое оборудование. Когда что-то выходит из строя в серверах, администраторы моментально реагируют.

Администраторы всегда носят с собой планшет, куда приходят уведомления о неполадках. А инженеры в диспетчерской следят за системой мониторинга, которая также позволяет быстро реагировать на любые события.
Как устроен мониторинг электроснабжения →
Механизм создания бэкапов
Есть много ситуаций, которые могут повлечь недоступность данных. Яркий пример — поломка диска или физического сервера. Или ситуация, когда пользователь удалил критически важные данные компании.
Чтобы не страшиться подобных сценариев, важно настроить бэкапы — резервные копии отдельных данных, приложений или снапшоты дисков. Более того, они должны располагаться на разных серверах и, желательно, в разных регионах. Самый безопасный вариант — хранить по меньшей мере три копии данных. Пару копий — на двух разных носителях, еще одну — на удаленной площадке.
Самостоятельно организовать такую систему бэкапов сложно. Раньше единственной страховкой от потери информации было самостоятельное использование систем хранения данных (СХД). Однако сегодня ответственность за сохранность данных и их бэкапов можно передать провайдеру.
Хороший пример
Бэкапы бывают полными, когда нужно сделать полную копию диска со всеми данными, и инкрементальными, когда нужно копировать только актуальные изменения. Для того, чтобы настроить их «по правилам» и не изобретать велосипед, можно воспользоваться готовыми решениями — например, технологиями от Veeam. Мы в Selectel предоставляем три сервиса для резервного копирования на базе этой платформы.
Один из вариантов — использовать Veeam Agent, софт для бэкапирования физических и виртуальных машин. При этом серверы могут располагаться в любом дата-центре, у любого провайдера или даже на on-premise площадке.
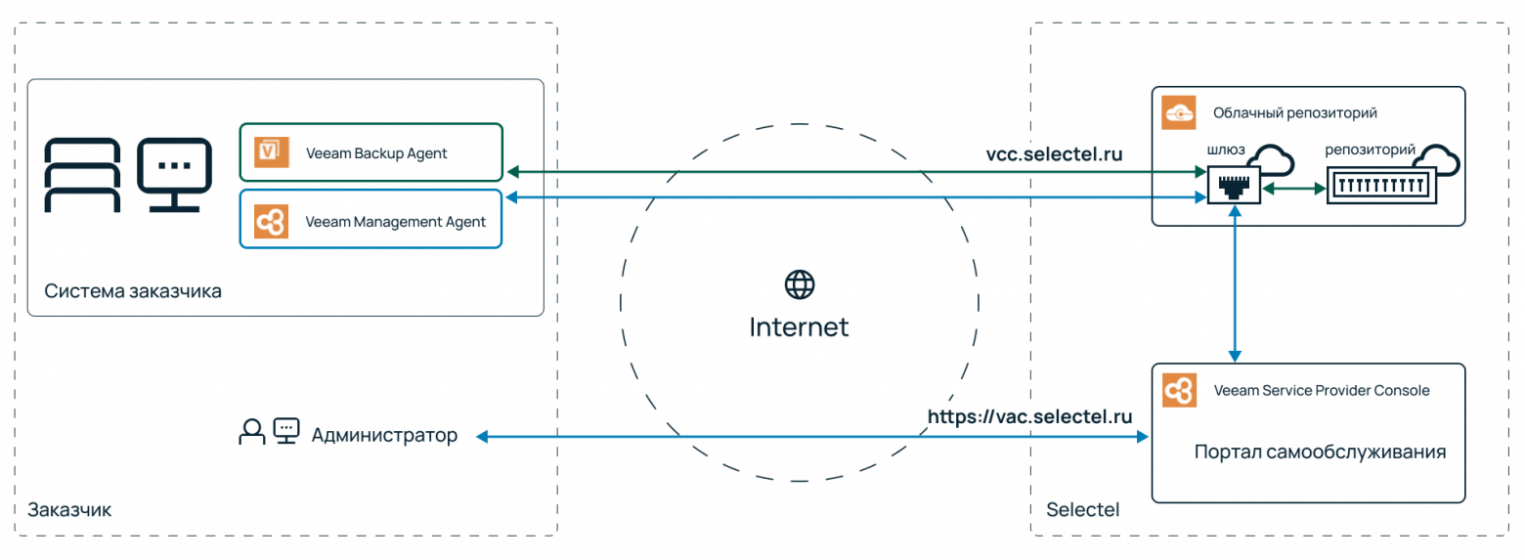
Катастрофоустойчивость
Предположим, вы храните все данные в одном месте. Это может быть один сервер, одна стойка, один дата-центр. Что произойдет, если эта единственная точка откажет? Данные, сервисы, приложения станут полностью недоступны. Решением этой проблемы будет так называемая устойчивость к катастрофам (катастрофоустройчивость). Чтобы не случилось с одной точкой хранения данных, на подхвате всегда будет вторая, которая сможет принять всю нагрузку на себя.
Хороший пример
Метеорит может упасть не только на дата-центр. Может задеть не только сервер, но и, например, оптоволоконное соединение между точками A и B, нарушив связность. Поэтому линки должны быть также зарезервированы.
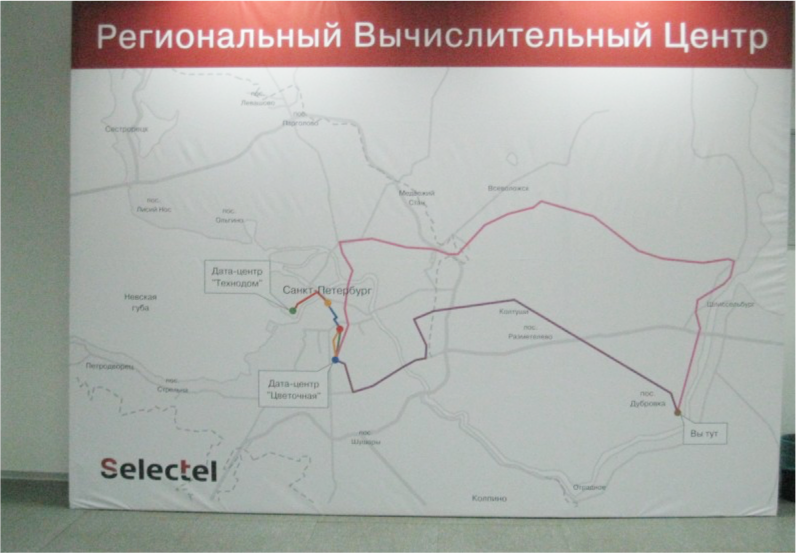
В 2010 году, когда мы начинали масштабировать сеть дата-центров, то сразу же зарезервировали подключения. Протянули кабели между Дубровкой и Цветочной вдоль двух железных дорог — верхнего и нижнего путей. Они удалены друг от друга, поэтому причина поломки первого соединения вряд ли скажется на втором.
Экскурс в сетевое резервирование →
Безопасность как важное условие отказоустойчивости
Обеспечение безопасности особенно важно в контексте отказоустойчивой IT-инфраструктуры. Необходимо настроить системы предотвращения угроз и восстановления после инцидентов.
На что важно обратить внимание
- Используйте файрволы. С помощью них можно блокировать нежелательный сетевой трафик и защищать внутренние системы от внешних угроз.
- Контролируйте доступы и MFA. Это можно реализовать в помощью инструментов идентификации и аутентификации.
- Используйте системы SIEM. Они собирают и анализируют данные из разных источников для выявления аномалий и инцидентов безопасности. Помогают быстро обнаруживать и реагировать на потенциальные угрозы.
- Своевременно обновляйте операционные системы, приложения и устройства. Так вы снизите риски, связанные с недоработками используемых решений и устраните уязвимости.
- Используйте системы резервного копирования и восстановления данных. Регулярные бэкапы и тестирование процедур восстановления позволяют обеспечить сохранность данных после инцидентов.
- Интегрируйте в инфраструктуру специализированные сервисы и оборудование для защиты от DDoS-атак. Это позволит предотвратить аварии из-за нештатной нагрузки сети и обеспечить непрерывную работу онлайн-сервисов.
- Обучайте свой персонал. Знание основ безопасности и социальной инженерии снижает риски кражи данных и, как следствие, возможных покушений на работу инфраструктуры.
Комбинация этих рекомендаций обеспечивает уровень безопасности, необходимый для отказоустойчивой IT-инфраструктуры.
Что поможет обеспечить отказоустойчивость
Для создания отказоустойчивости на уровне железа можно использовать специализированные компоненты, которые помогут избежать отказа одного из комплектующих. Среди них — например, ECC-память и RAID-массивы.
ECC-память — тип оперативной памяти, который в автоматическом режиме находит и исправляет спонтанно возникшие изменения в битах памяти. Такая память способна способна нивелировать изменение одного бита в одном машинном слове.
Для домашнего компьютера данный тип памяти не требуется, однако в продуктовых средах, где важно обеспечить бесперебойную работу компонентов, это обязательный компонент.
RAID-массивы — технология объединения нескольких физических дисков в один логический, которая позволяет системе пережить отказ одного или нескольких носителей информации.
Самые распространенные уровни RAID-массивов:
- RAID 0 — массив дисков с чередованием данных, в котором отсутствует резервирование;
- RAID 1 — массив, в котором данные «зеркалируются» между дисками, допустим выход из строя одного диска;
- RAID 10 — зеркальный массив с последовательной записью сразу на несколько дисков, допустим выход из строя одного-двух дисков;
- RAID 5 — массив дисков с чередованием блоков данных и контролем четности: данные циклически записываются на все накопители.
Из чего состоят отказоустойчивые кластеры
Отказоустойчивый кластер относится к группе независимых серверов, которые работают для поддержания высокой доступности приложений и служб. Если один из серверов выйдет из строя, другой возьмет на себя рабочую нагрузку, минимизировав простой. Этот процесс называют аварийным переключением.
В отказоустойчивом кластере серверы могут улучшить доступность и масштабируемость приложений и служб. При этом в качестве серверов могут быть как физические, так и виртуальные машины.
Виды кластеров
Существует два основных вида кластеров информационных систем — отказоустойчивые и с использованием балансировщика нагрузки.
Отказоустойчивый кластер (кластер высокой доступности) — это кластер, который продолжит свое функционирование, несмотря на потерю одного или нескольких узлов системы благодаря аппаратной избыточности.
С использованием балансировщика нагрузки — это подход с равномерным распределением входящей нагрузки между узлами, обслуживающими приложение. Балансировщик находится между конечными пользователями и серверами, обеспечивая одинаковое потребление ресурсов для всех серверов.
Типы кластеров
Отказоустойчивые кластеры делятся на три типа по резервированию: холодные, горячие и с модульной избыточностью.
Горячее резервирование — это метод, при котором все узлы системы обрабатывают входящие запросы. При выходе из строя одного узла нагрузка распределяется между остальными.
При холодном резервировании входящие запросы обрабатывает один из узлов, а остальные находятся в спящем режиме и включаются при выходе из строя основного сервера.
Модульная избыточность применяется в случае, когда даже минимальные простои недопустимы. В таком подходе узлы выполняют один и тот же запрос таким образом, что результат будет получен вне зависимости от их состояния.
Механизмы кластеризации
Репликация данных — это дублирование информации между двумя серверами. Приложения пишут данные в одну базу, а изменения автоматически сохраняются на другие.
Достоинства
- Рост отказоустойчивости. Если один из серверов выйдет из строя, остальные продолжат работу.
- Рост производительности. Эффективное распределение данных по разным регионам повышает скорость доступа к ним для местных пользователей.
Недостатки
При отказе мастер-сервера, на котором происходит запись данных, все реплики переходят в режим Read Only. В это время нельзя добавлять или удалять записи в базу.
Конфигурация master/slave
Кластер master/slave — это архитектурная конфигурация, в которой один сервер (мастер) управляет и контролирует другие компьютеры или серверы (слейвы). По сути, мастер-сервер принимает решения, а слейв-серверы просто выполняют команды и инструкции.
Этот тип конфигурации часто используют в системах и сетях для управления нагрузками. Наиболее распространенными вариантами будут базы данных и сетевое оборудование.
- Базы данных. В системах управления базами данных (СУБД) — например, MySQL или PostgreSQL — мастер-сервер принимает записи, а слейв-серверы реплицируют их.
- Сетевое оборудование. Существует подход, известный как Stacking (стекирование). Стекирование коммутаторов — это процесс объединения нескольких физических коммутаторов в одно логическое устройство. Они работают и управляются как единое устройство. Подробнее о технологии можно прочитать в нашей статье.
Конфигурация active/active
Конфигурация active/active — это архитектурный подход, при котором оба или все узлы активны и работают одновременно, обрабатывая запросы и трафик.
Это значит, что нагрузка равномерно распределяется между всеми узлами в системе, которые могут принимать и обрабатывать запросы вне зависимости от состояния других узлов. В этом случае обычно используют балансировщики нагрузки, которые маршрутизируют запросы клиентов до активных устройств или серверов.
Если одно из устройств выходит из строя, балансировщик автоматически перераспределяет трафик между оставшимися активными узлами. Таким образом, система продолжает работать непрерывно, даже если один из узлов перестал быть доступен.
Преимущества
- Рост производительности.
- Эффективное использование ресурсов.
- Оптимальное распределение нагрузки.
- Оперативная реакция на сбои.
Подход active/active часто используется в высоконагруженных сетевых и серверных средах, где непрерывная доступность и отказоустойчивость критически важны.




