Возможности PCI-E SSD Intel 910

Раньше у нас долгое время для кеширования random IO использовались intel 320 серии. Это было умеренно быстро, в принципе, позволяло сократить число шпинделей. При этом обеспечение высокой производительности на запись требовало, мягко говоря, неразумное количество SSD. Наконец, в конце лета к нам приехал Intel 910. Сказать, что я глубоко впечатлён — не сказать ничего. Весь […]
Раньше у нас долгое время для кеширования random IO использовались intel 320 серии. Это было умеренно быстро, в принципе, позволяло сократить число шпинделей. При этом обеспечение высокой производительности на запись требовало, мягко говоря, неразумное количество SSD.
Наконец, в конце лета к нам приехал Intel 910. Сказать, что я глубоко впечатлён — не сказать ничего. Весь мой предыдущий скепсис относительно эффективности SSD на запись развеян.
Впрочем, обо всём по порядку.
Intel 910 — это карточка формата PCI-E, довольно солидных габаритов (под стать дискретным видеокартам). Впрочем, я не люблю unpack-посты, так что перейдём к самому главному — производительности.
Описание устройства
Но сначала мы поиграем в Alchemy Classic, в которой если перетащить один LSI поверх 4х Hitachi, то получится Intel.
Устройство представляет собой особым образом адаптированный LSI 2008, к каждому порту которого «подключено» по одному SSD устройству ёмкостью 100Гб. Фактически все подключения выполнены на самой плате, так что подключение видно только при анализе взаимоотношений устройств.
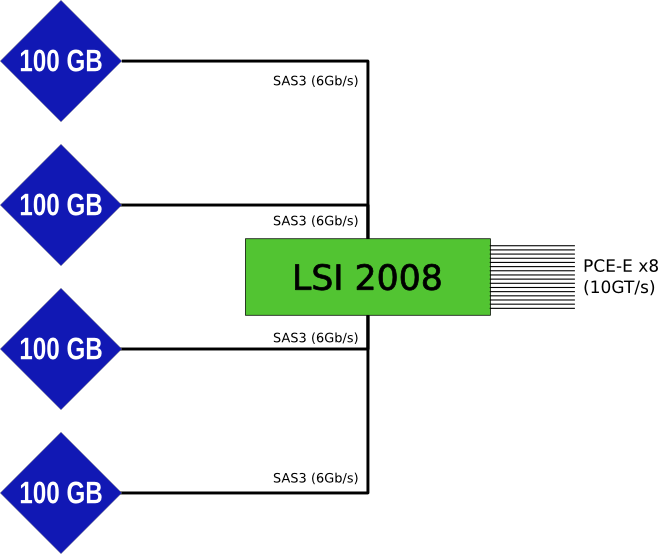
Примерная схема такая:
Заметим, LSI’ный контроллер перепилен очень сильно — у него нет своего биоса, он не умеет быть загрузочным. В lspci он выглядит так:
04:00.0 Serial Attached SCSI controller: LSI Logic / Symbios Logic SAS2008 PCI-Express Fusion-MPT SAS-2 [Falcon] (rev 03)
Subsystem: Intel Corporation Device 3700
Структура устройства (4 SSD’шки по 100Гб) подразумевает, что пользователь сам решит, как именно использовать устройство — raid0 или raid1 (для тонких ценителей — raid5, хотя с большой вероятностью это будет самая большая глупость, которую можно сделать с устройством подобного класса).
Обслуживается он драйвером mpt2sas.
К нему подключено 4 scsi устройства, которые объявляют себя hitachi:
sg_inq /dev/sdo Vendor identification: HITACHI Product identification: HUSSL4010ASS600
Никаких расширенных sata-команд они не поддерживают (так же как и большинство расширенных сервисных команд SAS) — только минимум необходимого для полноценной работы в качестве блочного устройства. Хотя, к счастью, поддерживает sg_format с опцией resize, что позволяет сделать полноценное резервирование для меньшего влияния housekeeping’а при активной записи.
Тестирование
Всего мы делали 5 разных тестов, позволяющие оценить характеристики устройства:
- тест на произвольное чтение;
- тест на произвольную запись;
- тест на смешанное параллельное чтение/запись (заметим, говорить про пропорции «чтения/записи» не приходится, т.к. каждый поток «молотил» отдельно друг от друга, конкурируя за ресурсы, как это чаще всего бывает в реальной жизни);
- тест на максимальную линейную производительность на чтение;
- тест на максимальную линейную производительность на запись.
Тесты на линейные чтение и запись
В общем случае, эти тесты мало кому интересны, для обеспечения «потока» HDD подходят куда лучше, т.к. у них выше ёмкость, ниже цена и весьма приличная линейная скорость. Простенький сервер с 8-10 SAS-дисками (или даже быстрыми SATA) в raid0 вполне способен забить десятигигабитный канал.
Но, всё-таки, вот показатели:
Линейное чтение
Для максимальных показателей мы выставили 2 потока по 256к на каждое устройство. Итоговая производительность: 1680МБ/с, без колебаний (девиация составила всего 40 мкс). Lantency при этом составила 1.2мс (для блока 256к это более чем хорошо).
Фактически, это означает, что в одиночку это устройство на чтение способно полностью «в потолок» забить канал 10Гбит/с и показывать более чем впечатляющие результаты на канале в 20Гбит/с. При этом оно будет показывать постоянную скорость работы вне зависимости от нагрузки. Заметим, сам Intel обещает до 2ГБ/с.
Линейная запись
Для получения самых высоких цифр по записи нам пришлось снизить глубину очереди — один поток на запись на каждое устройство. Остальные параметры были аналогичными (блок 256к)
Пиковая скорость (секундные отсчёты) составила 1800МБ/с, минимум — около 600МБ/с. Средняя скорость записи 100% составила 1228МБ/с. Внезапное снижение скорости записи — родовая травма SSD из-за работы housekeeping’а. В данном случае падение было до 600МБ/с (примерно в три раза), что лучше, чем в старых поколениях SSD, где деградация могла доходить до 10-15 раз. Intel обещает скорость порядка 1.6ГБ/с при линейной записи.
Random IO
Разумеется, линейная производительность никого не интересует. Всем интересна производительность под тяжёлой нагрузкой. А что может быть самым тяжёлым для SSD? Запись на 100% объёма, мелкими блоками, во много потоков, без перерывов в течение нескольких часов. На 320ой серии это приводило к падению производительности с 2000 IOPS до 300.
Параметры теста: raid0 из 4х частей устройства, делается linux-raid (3.2), 64-бита. Каждая задача с режимом randread или randwrite, для смешанной нагрузки описываются 2 задачи.
Заметим, в отличие от многих утилит, которые соотносят число операций чтений и записи в фиксированном процентном соотношении, мы запускаем два независимых потока, один из которых всё время читает, другой всё время пишет (это позволяет полнее нагрузить оборудование — если у устройства проблемы с записью, оно всё ещё может продолжать обслуживать чтение). Остальные параметры: direct=1,buffered=0, режим io — libaio, блок 4к.
Random read
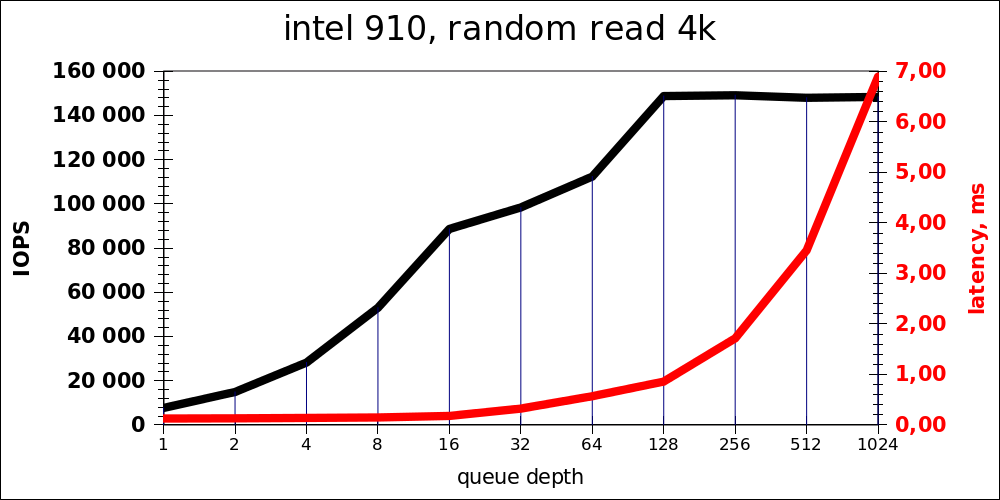
| iodepth | IOPS | avg.latency |
|---|---|---|
| 1 | 7681 | 0,127 |
| 2 | 14893 | 0,131 |
| 4 | 28203 | 0,139 |
| 8 | 53011 | 0,148 |
| 16 | 88700 | 0,178 |
| 32 | 98419 | 0,323 |
| 64 | 112378 | 0,568 |
| 128 | 148845 | 0,858 |
| 256 | 149196 | 1,714 |
| 512 | 148067 | 3,456 |
| 1024 | 148445 | 6,895 |
Заметно, что оптимальной нагрузкой является что-то порядка 16-32 операций одновременно. Очередь длинной в 1024 добавлена из спортивного интереса, разумеется, это не является адекватными показателями для product (но даже в этом случае latency получается на уровне довольно быстрого HDD).
Random write
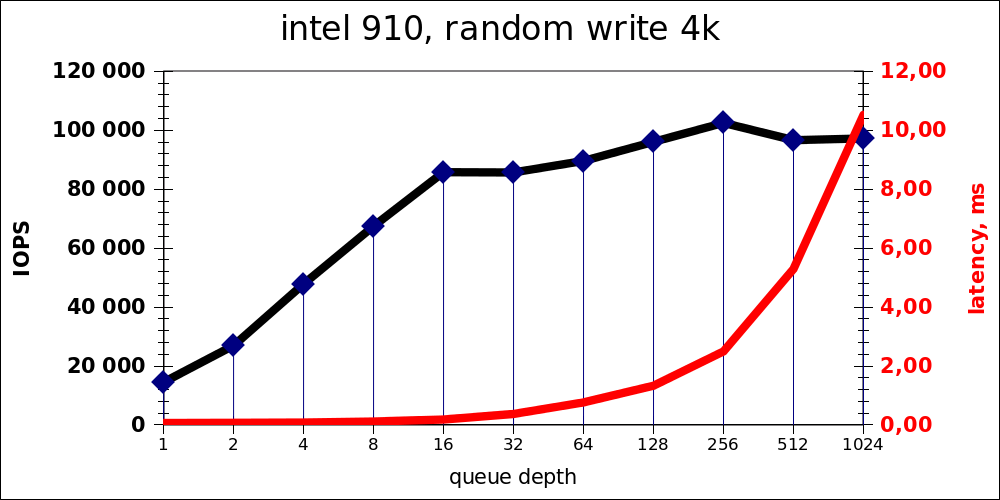
| iodepth | IOPS | avg.latency |
|---|---|---|
| 1 | 14480 | 0,066 |
| 2 | 26930 | 0,072 |
| 4 | 47827 | 0,081 |
| 8 | 67451 | 0,116 |
| 16 | 85790 | 0,184 |
| 32 | 85692 | 0,371 |
| 64 | 89589 | 0,763 |
| 128 | 96076 | 1,330 |
| 256 | 102496 | 2,495 |
| 512 | 96658 | 5,294 |
| 1024 | 97243 | 10,52 |
Аналогично — оптимум находится в районе 16-32 одновременных операций, путём весьма значительного (10-кратного роста) latency можно «выжать» ещё 10к IOPS.
Интересно, что на малой нагрузке производительность на запись выше. Вот сравнение двух графиков — чтения и записи в одном масштабе:
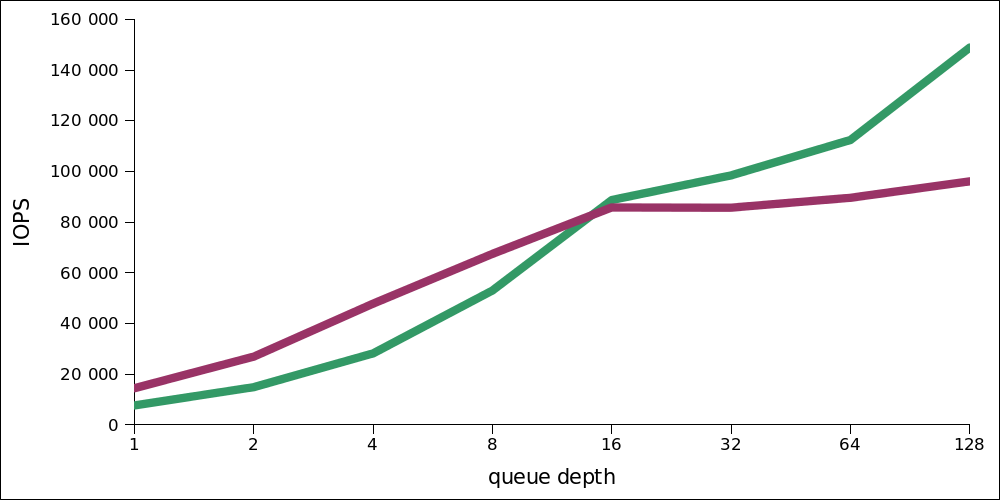
Смешанная нагрузка
Самый тяжёлый вид нагрузки, который можно считать заведомо превышающим любую практическую нагрузку в продакт-среде (включая OLAP).
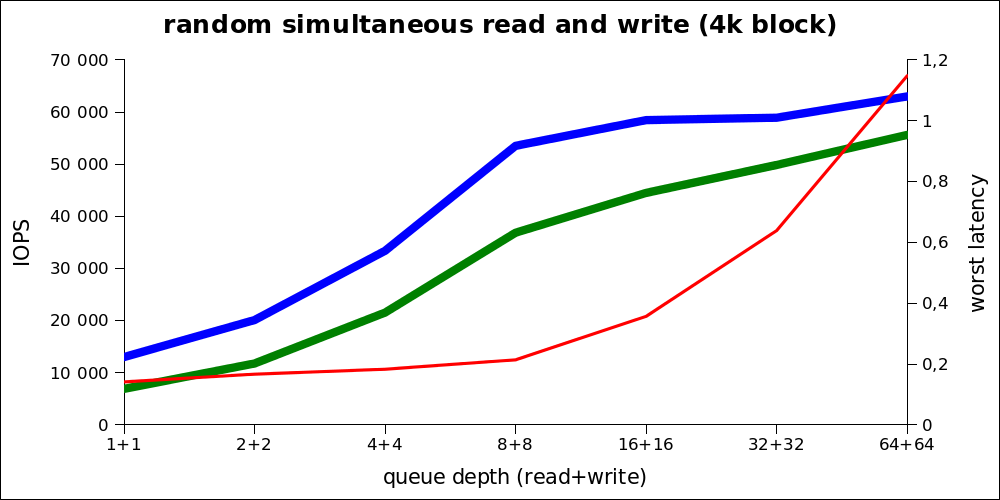
Поскольку по этому графику реальную производительность не понять, то вот те же цифры в куммулятивном виде:
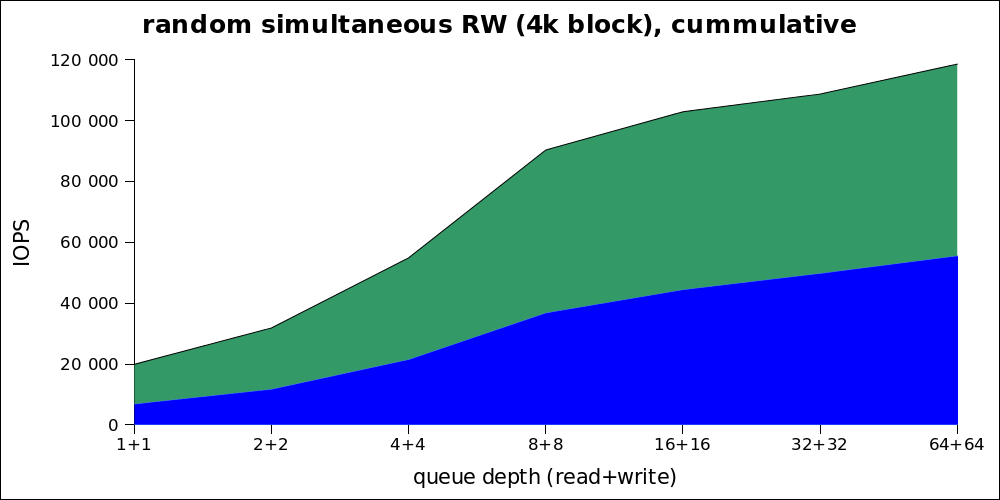
| iodepth | IOPS read | IOPS write | avg.latency |
|---|---|---|---|
| 1+1 | 6920 | 13015 | 0,141 |
| 2+2 | 11777 | 20110 | 0,166 |
| 4+4 | 21541 | 33392 | 0,18 |
| 8+8 | 36865 | 53522 | 0,21 |
| 16+16 | 44495 | 58457 | 0,35 |
| 32+32 | 49852 | 58918 | 0,63 |
| 64+64 | 55622 | 63001 | 1,14 |
Видно, что оптимальная нагрузка так же находится в районе от 8+8 (то есть 16) до 32. Таким образом, не смотря на очень высокие максимальные показатели, нужно говорить про максимум в ~80к IOPS при нормальной нагрузке.
Единственным минусом этого устройства являются определённые проблемы с горячей заменой – PCI-E устройства требуют обесточивать сервер перед заменой.


