Система учета IP-адресов


Немного о принципах IP-адресации
Прежде чем говорить о проблемах деления адресного пространства, вспомним основные принципы IPv4-адресации. IPv4-адрес представляет собой набор из 32 бит (единиц и нулей). Человеку прочесть и запомнить двоичный IP-адрес достаточно сложно. Поэтому 32 бита разделяются на четыре байта — так называемые октеты. Чтобы облегчить понимание, все октеты записываются в десятичной форме. Каждый IPv4-адрес состоит из двух частей: первая идентифицирует сеть, а вторая — узел в сети. Такая адресация называется иерархической: первая часть адреса идентифицирует всю сеть, в которой находятся все уникальные адреса. Маршрутизаторам нужно знать лишь путь к каждой сети, а не расположение отдельных узлов.
Чтобы узлы могли определить, где находится сетевая часть, а где — адрес узла, используется маска подсети. Маска подсети присваивается узлу одновременно с IP-адресом.Она представляет собой набор из 32 бит, в котором единицы соответствуют сетевой части, а нули — адресу узла. Сегодня широкое распространение получила запись IP-адресов в так называеой префиксной, или CIDR-нотации. Маска в такой записи указывается в виде числа после косой черты. Например, маска 255.255.255.0 в двоичном виде будет выглядеть так: 11111111.11111111.11111111.00000000. Количество единиц равняется 24, а маска записывается как /24.
Проблемы ручного выделения
Во многих организациях выделение IP-адресов осуществляется вручную, без использования каких-либо специализированных программных средств. Ручное выделение рано или поздно приводит к путанице с адресацией. Во-первых, ручное выделение неизбежно приводит к фрагментации: клиентам предоставляется много мелких подсетей, из-за чего становится невозможным выделить подсеть большего размера.
Во-вторых, необходимость выделять подсети разных размеров тоже приводит к различным трудностям.В качестве примера возможной проблемной ситуации можно привести случай, когда клиенту выделяется подсеть /27 или /28, из которой уже выделен блок /29. Можно ли как-то автоматизировать процесс выделения адресов, чтобы вообще избежать ошибок? Размышляя над этим вопросом, мы нашли свое решение, которое отлично работает благодаря хорошей визуализации.
Дерево интервалов и таблица свободных подсетей
Для поиска свободных подсетей мы используем дерево интервалов. С его помощью можно находить интервалы, пересекающиеся с заданным интервалом или точкой. IP-адрес можно представить в виде десятичного числа, так что мы можем без труда определить границы пула и представить все занятые подсети в виде отрезков на большом интервале.
Алгоритм поиска свободной подсети можно описать так. Предположим, что клиент просит выделить подсеть /27. Сначала нужно убедиться в том, что имеющийся пул по размеру больше, чем эта подсеть. Если он по размеру меньше, то нужно будет либо взять другой пул, либо сообщить клиенту об отсутствии свободных подсетей нужного размера. Если пул по размеру больше запрашиваемой подсети, то мы начинаем двигаться от начала пула отрезками размером в требуемую подсеть (ее размер равен 2^(32-x), где x — префикс подсети).
Используя ранее построенное дерево интервалов, мы можем быстро определить, перекрывает ли нужная клиенту подсеть, представленная в виде интервала, ранее выделенные подсети. Подсеть 127.0.0.0/27 в нашем примере перекрывает одну выделенную подсеть /29. Затем берется интервал, следующий за ней — 127.0.0.32/27. Мы проверяем его на пересечение с другими, и он оказывается свободен. После этого он предоставляется клиенту и помечается как занятый. Вся информация о свободных подсетях наглядно отображается в виде следующей таблице (зеленым цветом обозначены свободные подсети, синим — занятые, а серым — подсети, которые содержат уже занятые подсети более мелкого размера и поэтому не могут быть использованы):
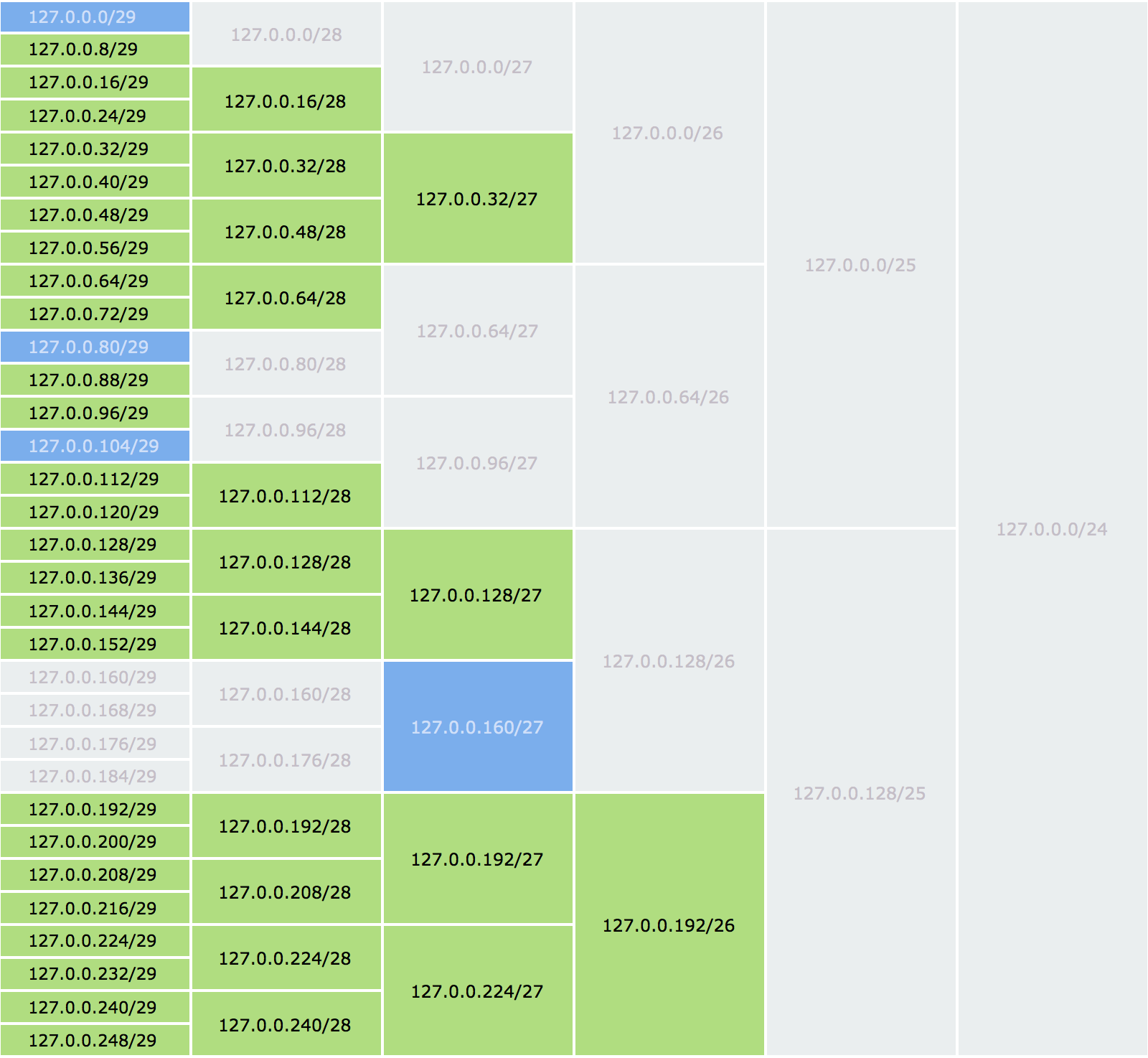
Чтобы ускорить поиск свободной подсети в пулах большого размера, можно проходить интервал циклом с разных сторон. Однако в таком случае масштабы фрагментации будут больше, и могут возникнуть проблемы с выделением крупных подсетей. Если мы нашли пересечение с подсетью большего размера (по сравнению с запрошенной клиентом), то мы можем следующий шаг цикла начать с ее конца, так как внутри этого интервала все равно отсутствуют свободные подсети.
Заключение
Предлагаемое нами решение по распределению IP-адресов делает управление адресным пространством более простым и, что немаловажно, более рациональным.
Конечно, его нельзя считать идеальным. Вопрос о рациональном и эффективном распределении адресного пространства остается открытым. Было бы интересно услышать от вас замечания и предложения по улучшению нашего подхода, а также ознакомиться с другими вариантами решения описываемой проблемы.




