Добровольные лимиты для облачных серверов

Новость одним абзацем: для облачных серверов появилась возможность задать лимиты для сервера. Лимитируется CPU и исходящий трафик. Не нравится быстро? Можно медленно! Мы вынесли в панель управления возможность выставлять самому себе лимиты на потребление ресурсов. Эти настройки по-умолчанию у всех виртуальных машин выставлены в «не ограничивать», что не отличается от поведения ранее. Область применения этих […]

Новость одним абзацем: для облачных серверов появилась возможность задать лимиты для сервера. Лимитируется CPU и исходящий трафик.
Не нравится быстро? Можно медленно!
Мы вынесли в панель управления возможность выставлять самому себе лимиты на потребление ресурсов. Эти настройки по-умолчанию у всех виртуальных машин выставлены в «не ограничивать», что не отличается от поведения ранее.
Область применения этих настроек (помимо «поиграться») — это исследование нового ПО или запуск приложений, в адекватности работы которых сомневаешься. Нужно понимать, что если программе нужно выполнить 100500 операций для своего завершения, то она их выполнит. Что со скоростью 500 операций в секунду, что со скоростью 100 операций в секунду. Вопрос исключительно и только в том, как долго это продлится.
Аналогично и для трафика. Если сервер решил отдать файл в 100500 Мб, то он его отдаст. Либо со скоростью 900Мб/с, либо со скоростью 1Мб/с — будет различаться только время операции.
… В том числе и время реакции человека на внезапную «неправильную» нагрузку. Одно дело, когда взбесившаяся программа ест 800% CPU и забивает интернет-канал в потолок, другое дело, когда «потолок» — 20% CPU и пара мегабит.
Как выглядят лимиты на практике?
Процессор
(техническая часть скороговоркой): параметр cap у cred-based скедулера Xen’а позволяет указать лимит, в пределах которого домен может быть запланирован на исполнение.
То же, но с расстановкой: Гипервизор позволяет ограничить виртуальную машину по времени, в течение которого она исполняется. Если виртуальная машина «успела» всё сделать до истечения лимита, то она «отдаёт» остаток времени гипервизору и лимит, таким образом, ей не заметен. Если же виртуальная машина достигает лимита, то гипервизор принудительно «забирает» у виртуальной машины управление и не отдаёт до начала следующего интервала. Сами интервалы короткие — 10 мс.
С точки зрения виртуальной машины этот лимит выглядит как steal time. Заметим, так как мы берём оплату по фактическому времени, в течение которого виртуальная машина использовала процессор, то steal time не оплачивается.
Как это выглядит?
Вот так вот выглядит загрузка системы в top с выставленным лимитом в 10% при запущенном cpuburn (утилита для прожигания денег):
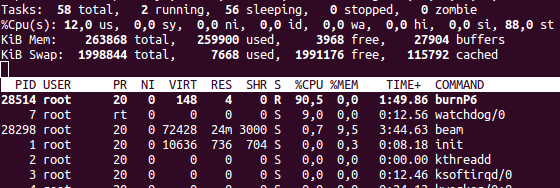
Кажется, что она заняла 90% CPU. На самом деле — 9%. Ещё один процент занят системными процессами. Заметим, если посмотреть, то stale (справа вверху) — 80%.
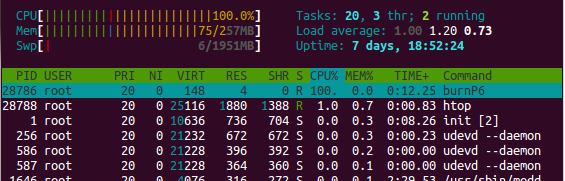
Вот то же самое, но с точки зрения htop:
И atop:
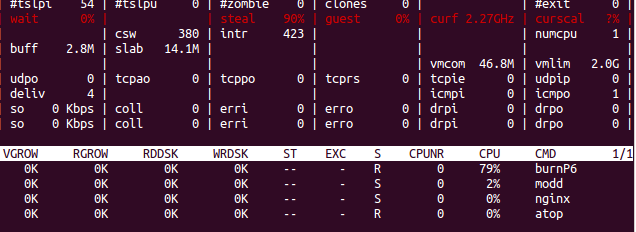
Заметим, atop в этом смысле умнее всех — он явно показывает, что серверу «недодают» процессорного времени.
Замечание по поводу steal: величина 1% на CPU (т.е. до 8% для 8 ядер) является нормальной для нелимитированных виртуальных машин — обработка и запросов на IO и сетевую активность в момент передачи данных в dom0 блокирует виртуальную машину в состоянии, похожем на steal, если это величина больше 10-15%, значит, вашей виртуальной машине недодают процессорного времени. Касается всех хостингов на Xen’е — и rackspace, и Amazon.
Сам по себе параметр позволяет лимитировать до 1% CPU, но даже на 10% машина становится несколько задумчивой, так что мы ограничили панель управления величиной в 5%, иначе пользователь рискует не дождаться завершения загрузки.
Исходящий трафик
(техническая скороговорка) Параметр qos_ratelimit_kpbs для netback позволяет ограничивать скорость передаваемых данных из домена.
Человеческое описание: паравиртуализированное сетевое устройство в Хen’е состоит из двух половинок. Одна — netfront, находится в виртуальной машине. Вторая половинка — netback — находится в dom0. Когда приходит трафик, адресованный виртуальной машине, он передаётся через довольно хитрый механизм трансфера страниц между доменами (его ещё называют zero copy) в виртуальную машину. Обратный процесс происходит аналогично.
Важно, что это процесс (как и всё в xen’е) кооперативный, то есть нужно одновременно и «желание» послать с одной стороны, и желание «принять» с другой. Если принимающая сторона не хочет принимать данные, то кольцевой буфер (специальная структура данных, находящаяся в общей памяти между доменами и использующаяся для координирования работы компонент) просто переполняется. Так как он «кольцевой», то у отправителя нет вариантов действий — либо он ждёт, пока получатель прочитает данные (и сдвинет указатели в кольцевом буфере), либо он затрёт данные о том, какие данные нужно отправить.
Таким образом, получатель имеет возможность ограничивать скорость приёма данных — достаточно всего лишь «медленнее читать».
Именно так и поступает netback (половинка драйвера сети в dom0), когда выставляются лимиты. Он всего лишь медленнее читает данные от сетевого адаптера виртуальной машины.
Возникает вопрос: а как же входящий трафик?
Ситуация тут совсем другая: трафик уже прислан. Мы его можем либо отбросить, либо передать. Если мы не успели передать, то трафик отбрасывается (иначе он начнёт копиться, забивая оперативную память). Лимитировать его по скорости не возможно, можно лишь отбрасывая избыточный. А это чревато значительной деградацией качества работы сети.
Из-за глупой ошибки величина сейчас указывается в килобайтах/секунду, в ближайшее время мы её приведём в нормальный вид c килобитами.
Вот как выглядит лимит на 4 Мбит/с на интерфейсе:




