Containerization Mechanisms: Cgroups

Today we’ll be continuing our post series on containerization mechanisms. In our last article on containerization, we talked about isolating processes using the namespaces mechanism. For containerization though, isolating resources isn’t enough. If we launch an application in an isolated environment, we should be sure it has been allocated enough resources and not use an inordinate amount, interrupting the rest of the system. For this task, the Linux kernel has a special mechanism, cgroups (short for control groups), which we will talk about today.
Cgroups is a particularly relevant topic today: kernel version 4.5, which was released in January of last year year, was officially equipped with the latest version of this mechanism: cgroup v2.
While working on it, cgroups was entirely rewritten.
Why did this require so many radical changes? To answer this question, let’s look at how the first version of cgroups came to be.
Cgroups: A Brief History
Development on cgroups was started in 2006 by Google employees Paul Menage and Rohit Seth. At that time, the term “control group” still wasn’t in use, and instead they used “process containers”. Naturally, their initial goal wasn’t to create the cgroups we see today. The original idea was much more modest: to improve the cpuset mechanism for distributing processor time and memory between tasks. But over time, everything grew into a much bigger project.
By the end of 2007, the name process container was replaced by control groups. This was done to avoid confusion with the term “container” (at that time, OpenVZ was in active development, and the word “container” was being used as we known it today).
In 2008, the cgroups mechanism was officially added to the Linux kernel (ver. 2.6.24). What was so new about this version?
Not a single system call for cgroups was added. As for the biggest changes, we should mention the cgroups filesystem, cgroupfs.
In init/main.c, references were added to functions that activate cgroups during bootup: cgroup_init and cgroup_init_early. Some less significant functions used for spawning and ending processes were modified: fork() and exit().
New directories were added to the /proc virtual file system: /proc/{pid}/cgroup (for each process) and /proc/cgroups (for the system as a whole).
Architecture
The cgroups mechanism is made up of two constituent parts: the core (cgroup core) and the subsystem. Kernel version 4.4.0.21 has 12 subsystems:
| name | Kernel module | function |
|---|---|---|
| blkio | block/blkcroup.c | Establishes limits for reading and writing on block devices |
| cpuacct | kernel/sched/cpuacct.c | For generating reports on processor resources used |
| cpu | kernel/sched/core.c | Gives processes access to the CPU under the control group |
| cpuset | kernel/cpuset.c | Divides tasks among processor cores under the control group |
| devices | security/device_group.c | Allows or blocks access to devices |
| freezer | kernel/cgroup_freezer.c | Suspends and restores task execution under the control group |
| hugetlb | mm/hugetlb_cgroup.c | Activates huge pages memory support for control groups |
| memory | mm/memcontrol.c | Manages memory distribution for process groups |
| net_cls | net/core/netclassd_cgroup.c | Marks network packets with a special tag for identifying packets spawned by a particular task in control group |
| net_prio | net/core/netprio_cgroup.c | Used for dynamically establishing traffic priorities |
| perf_event | events/kernel.c | Gives control groups access to perf_events |
| pids | kernel/cgroup_pids.c | Used for organizing a number of processes in a control group |
We can print a list of subsystems in the console using the command:
$ ls /sys/fs/cgroup/ blkio cpu,cpuacct freezer net_cls perf_event cpu cpuset hugetlb net_cls,net_prio pids cpuacct devices memory net_prio systemd
Each subsystem is a directory with control files where configurations are saved. The following control files can be found in each of these directories:
- cgroup.clone_children – allows you to transfer the settings from parent control groups to child groups
- tasks – contains a list of PIDs for all processes attached to the control group;
- cgroup.procs – contains a list of TGIDs for process groups attached to the control group
- cgroup.event_control – allows you to send notifications if the status of a control group changes
- release_agent – contains commands that are executed if the notify_on_release option is enabled.RequestThis can be used for automatically deleting empty control groups
- notify _on_release – contains a boolean variable (0 or 1), enabling (or disabling) the execution of the command given in release_agent
Each subsystem also has its own control files. We’ll discuss some of these below.
To create a control group, we just create an embedded directory in a subsystem. Control files will automatically be added to these embedded directories (which we’ll discuss in more detail below). Adding processes to a group is fairly simple: you just need to write their PID to the tasks control file.
The aggregation of control groups embedded in a subsystem is called a hierarchy. We’ll look at the principles of cgroups functions with some practical use examples.
Cgroups Hierarchy: Practical Orientation
Example 1: Managing CPU Resources
We execute the command:
$ mkdir /sys/fs/cgroup/cpuset/group0
With this command, we can create a control group containing the following control files:
$ ls /sys/fs/cgroup/cpuset/group0 group.clone_children cpuset.memory_pressure cgroup.procs cpuset.memory_spread_page cpuset.cpu_exclusive cpuset.memory_spread_slab cpuset.cpus cpuset.mems cpuset.effective_cpus cpuset.sched_load_balance cpuset.effective_mems cpuset.sched_relax_domain_level cpuset.mem_exclusive notify_on_release cpuset.mem_hardwall tasks cpuset.memory_migrate
There aren’t any processes in our group at the moment. To add a process, we need to write its PID to the tasks file:
$ echo $ > /sys/fs/cgroup/cpuset/group0/tasks
The $$ symbols stand for the PID of the process being executed by the current command shell.
This process is not attached to any single CPU core, which we can verify with the following command:
$ cat /proc/$/status |grep '_allowed' Cpus_allowed: 2 Cpus_allowed_list: 0-1 Mems_allowed: 00000000,00000001 Mems_allowed_list: 0
The printout from this command shows us that 2 CPU cores, numbered 0 and 1, are available for this process.
We’ll try to “attach” this process to core number 0:
$ echo 0 >/sys/fs/cgroup/cpuset/group0/cpuset.cpus
Let’s see the results:
$ cat /proc/$/status |grep '_allowed' Cpus_allowed: 1 Cpus_allowed_list: 0 Mems_allowed: 00000000,00000001 Mems_allowed_list: 0
Example 2: Managing Memory
We’ll embed the group we created in the previous example in another subsystem:
$ mkdir /sys/fs/cgroup/memory/group0
Then we execute:
$ echo $ > /sys/fs/cgroup/memory/group0/tasks
We’ll try to limit memory usage for control group 0. For this, we’ll have to enter said limit in the file memory.limit_in_bytes:
$ echo 40M > /sys/fs/cgroup/memory/group0/memory.limit_in_bytes
The cgroups mechanism has comprehensive memory management. For example, it can be used to protect critical processes from falling under the hot hand of OOM-killer.
$ echo 1 > /sys/fs/cgroup/memory/group0/memory.oom_control $ cat /sys/fs/cgroup/memory/group0/memory.oom_control oom_kill_disable 1 under_oom 0
If we were to place the ssh daemon in a separate control group, for example, and turn off OOM-killer for that group, then we could be sure that it wouldn’t “die” under the growing memory usage.
Example 3: Managing Devices
We’ll add our control group to another hierarchy:
$ mkdir /sys/fs/cgroup/devices/group0
By default, the group isn’t prohibited from accessing any device:
$ cat /sys/fs/cgroup/devices/group0/devices.list a *:* rwm
We’ll try to set a restriction:
$ echo 'c 1:3 rmw' > /sys/fs/cgroup/devices/group0/devices.deny
This command adds the device /dev/null to our control group’s list of restricted devices. We wrote the line ‘c 1:3 rmw’ to our control file. We first enter the kind of device—in our case, this is a symbol device marked by the letter c (short for character device). Two other kinds of devices are block (b) and all devices (a). Then we have the device’s major and minor number. You can find a device’s number using the command:
$ ls -l /dev/null
Instead of /dev/null you can enter any path. The printout will look like this:
crw-rw-rw- 1 root root 1, 3 May 30 10:49 /dev/null
The first digit in the printout is the major number, and the second is the minor.
The last three letter represent the access rights: r — permission to read files from the given device; w — permission to write to the given device; m — permission to make new device files.
Next we execute:
$ echo $ > /sys/fs/cgroup/devices/group0/tasks $ echo "test" > /dev/null
When executing the last command, the system returns an error message:
-bash: /dev/null: Operation not permitted
We cannot interact with /dev/null because access is blocked.
We’ll restore access:
$ echo a > /sys/fs/cgroup/devices/group0/devices.allow
After running this command, the entry a *:* nwm will be added to the file /sys/fs/cgroup/devices/group0/devices.all and all restrictions will be lifted.
Cgroups and Containers
From these examples, we can see the principles behind cgroups: we place specific processes in groups, which we can then “embed” in subsystems. Now we’ll look at more complicated examples to see how cgroups is used in modern containerization tools. For these examples, we’ll be using Lxc.
We’ll install LXC and create a container:
$ sudo apt-get install lxc debootstrap bridge-utils $ sudo lxc-create -n ubuntu -t ubuntu -f /usr/share/doc/lxc/examples/lxc-veth.conf $ lxc-start -d -n ubuntu
We’ll see what changed in the cgroups directory after creating and launching the container:
$ ls /sys/fs/cgroup/memory cgroup.clone_children memory.limit_in_bytes memory.swappiness cgroup.event_control memory.max_usage_in_bytes memory.usage_in_bytes cgroup.procs memory.move_charge_at_immigrate memory.use_hierarchy cgroup.sane_behavior memory.numa_stat notify_on_release lxc memory.oom_control release_agent memory.failcnt memory.pressure_level tasks memory.force_empty memory.soft_limit_in_bytes
As we can see, every hierarchy now has an lxc directory, which itself contains an Ubuntu directory. For every new container in the lxc directory, a separate subdirectory will be created. The PID of all of the processes that can be launched in this container will be written to the file /sys/fs/cgroup/cpu/lxc/[container name]/tasks.
Resources can be allocated for containers using cgroups control files and the lxc command:
$ lxc-cgroup -n [container name] memory.limit_in_bytes 400
This can similarly done for Docker, systemd-nspawn and other containers.
Drawbacks to Cgroups
Throughout its nearly 10 years of existence, cgroups has been subject to criticism on more than one occasion. As the author of one LWN.net article has pointed out, developers “love to hate” the cgroups core. We may be able to understand this from the examples we’ve looked at in this article, although we tried to be as neutral as possible: embedding a control group separately into each subsystem is very inconvenient. If we look carefully, we’ll see that this approach is extremely inconsistent.
If we, for example, create an embedded control group, then the parent group’s configuration will be inherited in some subsystems, but not in others.
In the cpuset subsystem, any change to the parent control group is automatically made to the embedded groups, but other subsystems don’t do this, and the clone.children parameter has to be activated.
There was talk of troubleshooting these and other issues in the kernel developer’s community a long time ago: one of the first texts on this topic dates back to the start of 2012.
The author of this text, Facebook engineer Tejun Heo, directly points out that the main problems with cgroups is its improper organization method, whereby subsystems connect to multiple control group hierarchies. He suggested using one, and only one, hierarchy and to add subsystems for each group separately. This approach involved serious changes, including a name change: the mechanism for isolating resources is now called cgroup (singular) and not cgroups.
We’ll take a closer look at these innovations.
Cgroup v2: What’s New
As we stated above, cgroup v2 has been included in the Linux kernel as of version 4.5. The old version is also supported. For version 4.6, there is already a patch that lets you turn off first-version support when downloading the kernel.
Currently, cgroup v2 can only work with three subsystems: blkio, memory, and PID. Patches have already been released (test releases) which let you manage CPU resources.
Cgroup v2 is mounted with the following command:
$ mount -t cgroup2 none [monitoring point]
Let’s say we mounted cgroup v2 in the /cgroup2 directory. The following control files will automatically be created in this directory:
- cgroup.controllers – contains a list of supported subsystems
- cgroup.procs – once mounted, it contains a list of all the processes executed in the system, including zombie processes. If we create a group, then the same kind of file will be created for it; it will remain empty until processes have been added to the group.
- cgroup.subtree_control – contains a list of active subsystems for a given control group; empty by default
These files are created in every new control group. The file cgroup.events, which is empty in the root directory, is also added to each group.
New groups are created by running:
$ mkdir /cgroup2/group1
To add a subsystem to a group, the subsystem name has to be entered in the file cgroup.subtree_control:
$ echo "+pid" > /cgroup2/group1/cgroup.subtree_control
To delete a subsystem, the same command is used but with a minus sign instead of a plus sign:
$ echo "-pid" > /cgroup2/group1/cgroup.subtree_control
When a subsystem is activated for a group, additional control files are added to it. For example, after activating the PID subsystem, the files pids.max and pids.current will be created in the directory. The former file is used for organizing the number of processes in a group, while the second contains information on the number of processes active in the group at that moment.
Subgroups can be created in existing groups:
$ mkdir /cgroup2/group1/subgroup1 $ mkdir /cgroup2/group1/subgroup2 $ echo "+memory" > /cgroup2/group1/cgroup.subtree_control
All subgroups inherit the parent group’s properties. In the last example, the PID subsystem will be activated for group1 and all subgroups embedded in it; pids.max and pids.current will also be added to them. This can be demonstrated with the following diagram:
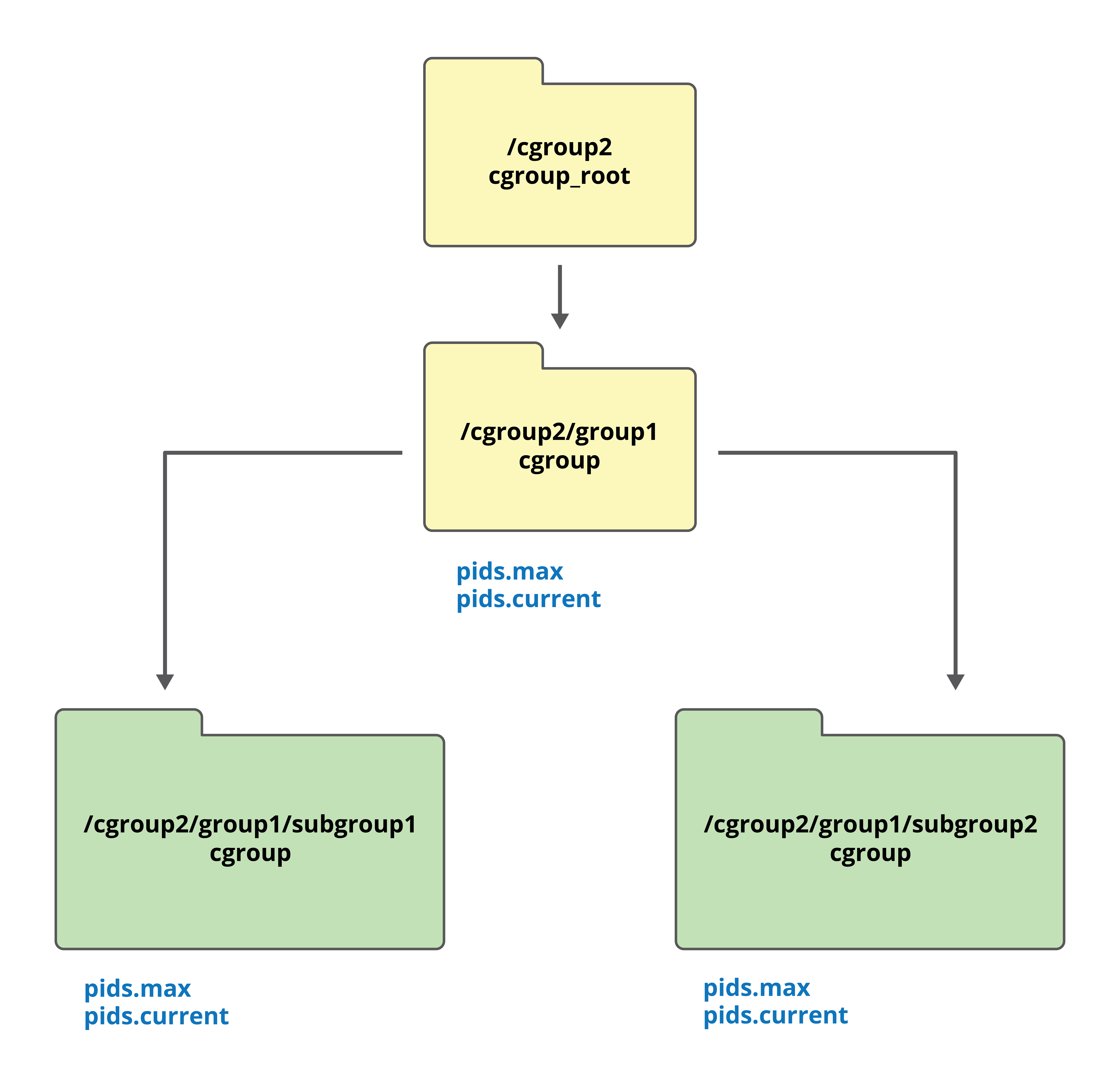
To avoid any misunderstanding about embedded groups (see above), cgroup v2 observes the following rule: don’t add a process to an embedded group if any subsystem in it is activated:
In the first version of cgroups, processes could enter several subgroups at one time, even if these subgroups were part of different hierarchies and embedded in different subsystems. In the second version, one process may belong only to one subgroup, avoiding any confusion.
Conclusion
In this article, we looked out how cgroups is build and which changes were introduced in the new version. If you have any questions or anything to add, please do so in the comments below.
For anyone wishing to read more about this topic, below you will find links to relevant materials:
- https://www.kernel.org/doc/Documentation/cgroup-v1/cgroups.txt — documentation for the first version of cgroups
- https://www.kernel.org/doc/Documentation/cgroup-v2.txt — documentation for cgroup v2
- https://www.youtube.com/watch?v=PzpG40WiEfM — Tejun Heo’s lecture on innovations to cgroup v2
- https://events.linuxfoundation.org/sites/events/files/slides/2014-KLF.pdf — a presentation on cgroup v2 with elaborations of all the innovations and changes (PDF)